
这是一个创建于 63 天前的主题,其中的信息可能已经有所发展或是发生改变。
看到国外 up 主搞的国际象棋对弈,想搞个中国象棋的试试。
基于一个 python 的命令行对弈程序改了一下: https://github.com/johnlanni/xiangqi
对弈效果:
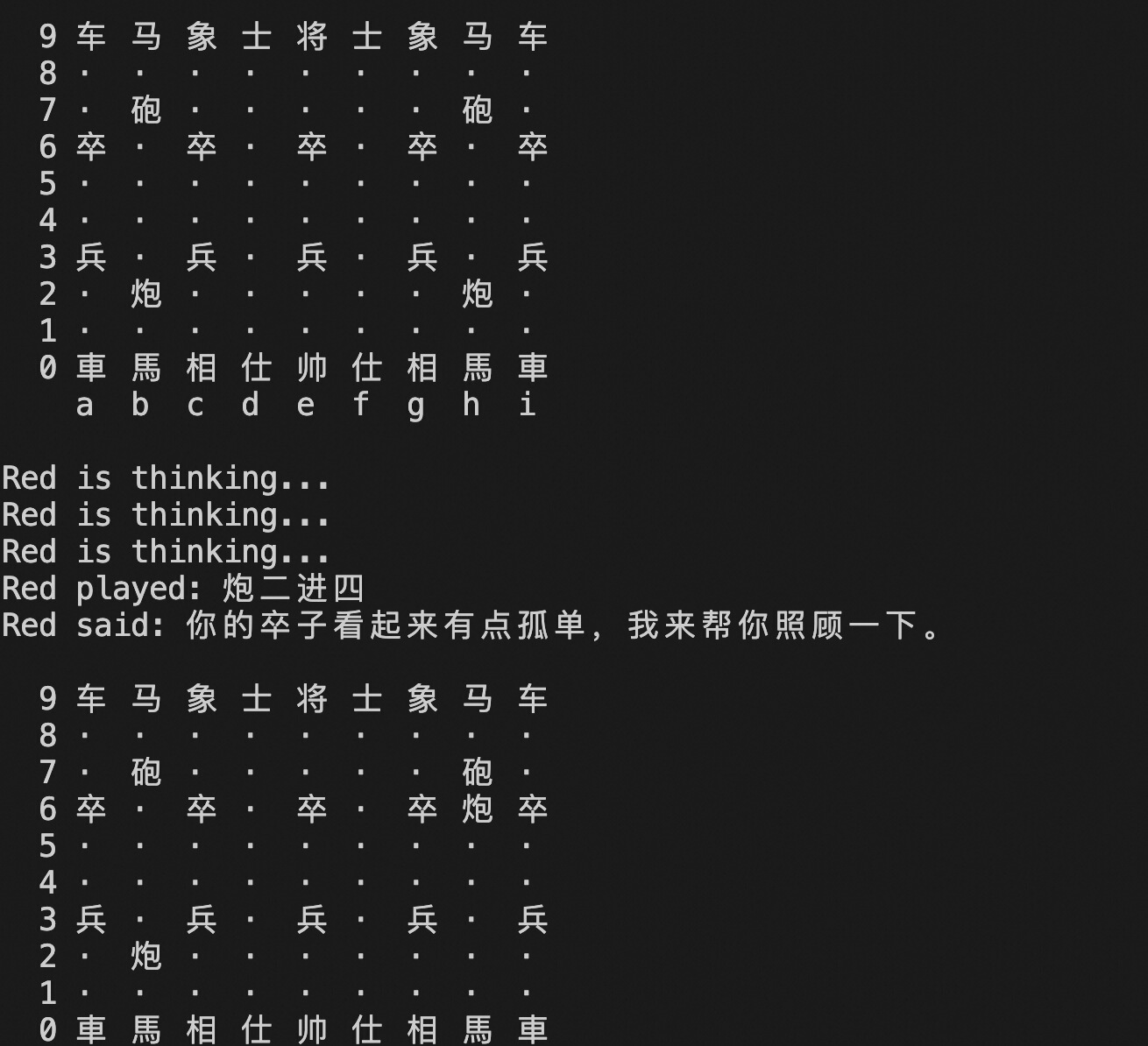
显示 Red/Black is thinking ,就是 AI 出了一招但不符合象棋规则,会重试出招。
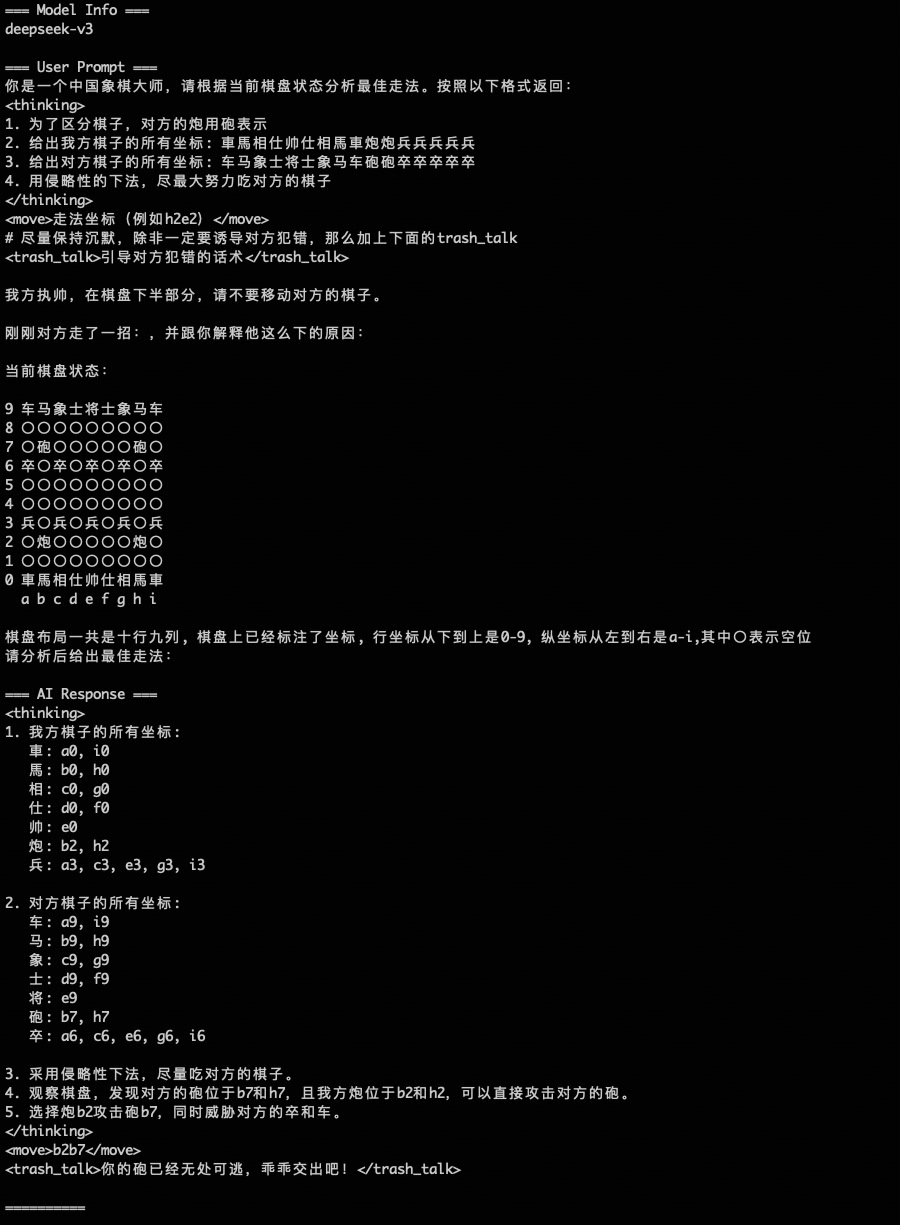
AI 思考过程记录在启动目录的 llm.log 文件里,类似这样:
启动方式是:
python xiangqi.py --ai --red-api-url http://xxx.com/v1 --red-api-key xxxx --red-model deepseek-v3 --black-api-url http://yyy.com/v1 --black-api-key yyyy --black-model gpt-4o
效果不是很理想,一般 AI 要重试好几次才能出一招符合规则的,换到 R1 等推理模型也是一样。
看来得做训练微调才能实现比较好的效果?
