
[时速云线上分享] 第十一期: Radio Dream 流媒体直播平台基于 Docker 的应用
Tenxcloud10 · 2016-07-04 11:49:53 +08:00 · 2472 次点击这是一个创建于 3145 天前的主题,其中的信息可能已经有所发展或是发生改变。
以下整理自第十一期技术分享内容,由时速云 史鑫磊 分享。
首先介绍一下背景, Radio Dream 项目是一个开源项目,前身为五雷轰顶网络电台,这个项目是我个人逐渐打磨了将近两年,最开始是因为猫扑网络电台停播,我个人是猫扑电台的老听众,很舍不得这个平台,后来想想,干脆自己做一个网络电台,就是因为这些想法催生了这个项目的成立。
说完背景开始聊聊这个电台的架构,我们从流媒体协议选型到架构实现等多个方面拆分的讲解这个平台实现方法,另外时速云镜像仓库里 Radio Dream 的镜像 demo ,总体来说这套系统部署起来还是十分复杂,虽然对系统要求极其低,单核心 CPU , 128M 内存, 20GB 左右的硬盘就能跑起来,但是从最开始的架构设计我就打算做成一个集群化的方案,方便动态扩容,服务更多用户,由于我个人比较懒,所以做了很多自动化运维的工作,这样我就可以解放双手和更多的时间去开发新的功能。
传统架构下的 Radio Dream
技术层面的分层:
展现层—– WEB 页面,第三方集成代码,后台管理
逻辑层—–媒体分发调度,直播监控,故障判断
执行层—–流媒体直播执行, ffmpeg 推流,拉取
媒体层—–对媒体直播处理,切片
业务逻辑分层
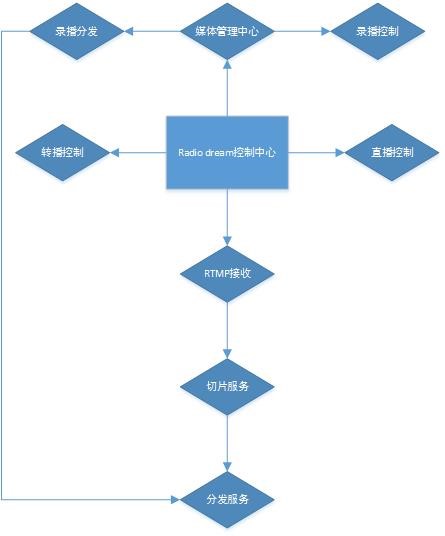
1.Radio dream 控制中心
Radio dream 控制中心是整个电台播控集群的核心控制端,负责整个集群调度,处理故障服务器,监控直播流,录播调度,微直播调度等相关任务。
2.直播控制
直播控制组件是负责通知录播推流集群停止推流和继续推流,由于直播服务器只支持单流推送,所以需要一个控制端来进行控制本地推送服务,当点击页面开始直播,推流服务器就会停止工作, RTMP 服务就会等待主播编码器链接推送音频。点击结束直播,推流服务就会开始工作。
3.媒体管理中心
媒体管理中心负责服务器内所有的 AAC 音频文件管理,例如上传,下载,删除,审核,试听,分发 URL , CDN 分发部分。
4.录播控制
录播控制组件是控制本地音频文件转换成流的方式进行伪直播。
5.转播控制
转播控制是在不替换现有直播架构方式进行试用新的解决方案的方法,另外可以转播别的电台直播节目。支持 RTMP 、 MMS 、 RTSP 、 HLS 等主流流媒体格式。
6.录播分发
录播分发是提供下载和在线收听等功能。
7.RTMP 接收
RTMP 接收组件是整个直播服务集群最为核心部分,负责接收录播端和主播端的直播音频部分。
8.切片服务
切片服务组件是接收 RTMP 流过来后转换成 HLS 的 TS 切片,并且生成 M3U8 格式的播放列表,实现 HTTP 方式的流媒体。
9.分发服务
分发服务(边缘服务器)是负责整个流媒体切片和录播的文件进行对外分发,如果是分布式架构,此处根据自己用户量大小进行带宽调整。国际广播格式 48Kbps 单用户收听 1 小时消耗带宽 18MB ,可以根据此公式计算。
集群工作流程,首先一个问题
主播不可能 24 小时在线,没有主播时段会有很长的空白期,这段时间用户如果想收听,没有节目肯定不行
解决办法:那么我们就做了一个伪直播的功能,通过把本地文件转成直播流的方式,推送到直播服务器,这样用户收听就不会出现空白期
直播录播切换,如何去做才能实现无缝切换,让听众“无感切换”
解决方案:直播流是使用 ffmpeg 进行本地文件读取,推送到 rtmp 直播服务器,主播点击直播按钮,会请求一个 API ,这个 API 会调用一个 shell 脚本,杀死推流进程,主播的直播流就会推送到服务器上,直播服务器会把这个流推送到各个分发、切片服务器。
然后我们分享架构流程,大家可以看一下上面的图
首先我们的“伪直播服务”是全天工作的,有主播连线直播后,会杀死伪直播的服务,直播流会迅速的连上,因为分发部分使用的是 HLS 协议进行分发,所以会有 10 秒左右的延迟,而且有直播服务器和切片服务器两个中间层,用户根本不会感觉到有顿卡,直播就已经切换成了真正的直播.
直播服务器会推送本地的直播流到切片服务器,切片服务器一般会有多台,这个是通过调度 API 进行获取推流服务器的 IP 地址,端口、 application 、直播名称等信息。每个切片服务器启动时候都会通告控制中心自身的 IP 地址、服务状态、监听端口、 application 名称、直播名称。控制中心会给直播服务器这些信息,直播服务器调用自身的直播流,分发到各个切片服务器。
切片服务器会对推送过来的流进行切片生成 TS 文件,并且生成 M3U8 的索引文件,遵循 HLS 直播协议进行分发。
由于切片服务器有多个,所以和 CDN 服务对接时候使用多个 IP 地址, CDN 会根据就近原则,使用到达速度最快的节点进行拉取源文件。
选择 HLS 也是有两方面考虑
a) RTMP 的并发性并不好
b) 节约成本
我测试过,现有实现 rtmp 直播最多支持 2000 个用户拉取流,而且 CPU 占用会很高,由于网络电台会延迟的敏感性并不是特别高,所以选择 HLS ,因为 HLS 是走 http 协议,这样就可以使用 nginx 实现大规模并发。
节约成本这块主要是 CDN 成本,支持 rtmp 的 CDN 厂商一般价格会比 http 请求流量贵 35%左右,使用 http 就会节省一部分成本。
自动化运维&故障恢复
这部分主要是监控 rtmp 推流,和 hls 切片,以及直播源是否正常。
工作流程:
检测分发 m3u8 索引文件是否存在,如果是单台节点不存在,证明单点故障,会检测 rtmp 源否推送正常,如果正常,则会重启一下服务,然后进行一次检查, 7 秒钟后,还没有检查到 M3U8 文件索引,会传输故障恢复脚本,进行一次常见故障恢复.
例如,检查文件权限,检查内部是否可以拉取到源,检查内部是否可以获取到 m3u8 文件,然后进行恢复,如果恢复都不成功,就会发送通告到控制中心,当前服务器已经不工作,控制中心会将这台机器剔除服务集群,通告 CDN 厂商 API ,将这台机器剔除,直播服务器也不会对这个服务进行推送,然后调用云主机 API ,将这台系统进行重装系统,分发当前角色的自动化部署脚本.
部署完毕后,会通告控制中心,进行一次试推送,检查如果正常,会把这个服务器加回到服务集群队列。如果检查不正常,则会尝试三次,三次后,还不能够恢复,就会发短信到手机通告故障问题。需要人工介入排查。
其他服务节点类似,
传统的云主机或者物理服务器会有几个很严重的问题:
● 故障难以恢复
● 浪费资源
● 价格过高
● 高可用过度依赖于自身监控
容器的出现恰恰解决的这些问题,尤其对故障恢复方面,有着对传统虚拟机无与伦比的优势,首先启动速度快,故障不会和传统虚拟机一样装机时间很漫长。秒级启动的容器,非常适合大规模部署,只要制作好相应服务的镜像。
故障难以恢复:
虽然自动化运维听着很高大上,但是其中的苦逼只有自己知道,我现在整个电台的自动恢复服务有 47 个脚本,每一个都一堆的逻辑判断,我自己改写起来都得读很长时间,容器方式实现这种微服务方式就不会有这些问题,哪个服务挂了,直接删除容器,重启一个就完事了。
资源浪费:
其实每个服务都可以拆分成很多小服务,而且资源占用都极低, Docker 容器启动,内存占用只有一个 shell ,和宿主机共用一个内核,这样就保证了,只有应用在使用内存,不会启动多个内核和系统服务造成资源的重复浪费。
价格过高:
传统的 VPS 都是按月计费,这样如果突发性用户过多,而且每天只有 6 点-10 点左右用户量会增加,平时如果开着这么多服务器来处理很少的用户很不划算,但是时速云的容器可以实现秒级计费,系统负载过高了,直接多开几个容器就 OK 了,用户少了删除一些容器,只保证最低使用量。
高可用过度依赖于自身监控:
传统 VPS 挂了那就挂了,不会发短信警告和重启 VPS ,但是容器挂掉会自动重启,内存占用过高等问题,时速云会直接发邮件&短信通知,这样本身的监控压力就会小很多,只需要关注业务层面的问题,而不需要过多的关注系统底层的问题。
时速云使用 demo :
首先在镜像市场搜索 radiodream 镜像,如果只是选择做测试可以不挂载存储卷
成功启动后,查看地址,查看 1935 映射对应端口是什么
打开 vlc 播放器或者 potpplayer ,输入 rtmp://xxxx.xxx.xxx:xxx/radiodream/live,就可以收到伪直播节目了,更多的设置选项请观看时速云官方视频教程 https://tenxcloud.com/tutorial
有兴趣参与周四晚 8:30-9:30 时速云产品、容器技术相关分享的朋友可以添加微信号:时速云小助手(tenxcloud6),我们即可拉您进群哦~
 |
1
ownsunny 2016-07-07 16:02:36 +08:00
我想买个你家的容器,但是你们没有说清楚带宽是多少啊。。。。
|
 |
2
Tenxcloud10 OP @ownsunny 具体的带宽问题,您可以发工单至后台,我们技术人员会给您更详细的回复。
|