
这是一个创建于 3071 天前的主题,其中的信息可能已经有所发展或是发生改变。

有状态应用程序可以被容器化吗?或者容器只适合无状态的应用程序吗?本文带你一见分晓。
Docker Engine 等容器技术为应用提供了标准打包和运行时环境。
容器能快速部署,并有效地利用系统资源。开发人员使用容器技术,换取的是应用程序的可移植性和可编程的镜像管理。运维团队使用容器,可以以标准化的方式部署和管理运行时单元。
除了这些已知的优点,我们对容器都有一个普遍的误解:容器是短暂的,所以只能运行无状态的微服务应用,而不能运行有状态的服务。下面我们看看这个观点是否成立。
理解”状态”(state)
应用程序的状态是应用程序组件完成他们工作(即执行一个任务 )所需的数据。任何应用程序都有状态。软件编程架构模式、范式和语言从根本上描述如何管理应用程序的行为(任务,操作等)和状态(数据)。
即便微服务应用也有状态!
在微服务架构中,每个服务可以有多实例,每个服务实例都被设计成无状态的。这意味着,任何一个实例存储跨操作的数据。
无状态,只是意味着服务实例不能为了执行一个行为,从其它地方获取数据。
这是微服务式应用的一个重要架构限制,因为它强化了敏捷和弹性,并允许任何可用的服务实例来执行任何任务。
通常情况下,应用程序状态被存储在数据库、缓存、文件或其他存储的形式中。任何需要跨操作使用的状态变化都必须被写回到存储中。
因此,任何应用都有状态,但如果把程序行为和数据分离开,应用程序的组件可以是无状态的,它在执行行为时能够获取到数据即可。但是,这似乎只是简单地把问题传给其他东西-其他组件如何管理状态?为了方便更深入地讨论,首先看看状态的五个分类:
要回答上面的问题,让我们考虑一下应用程序可能会有的 5 种状态类型,以及我们如何应对每一个状态的应用容器化:
1.持久状态 (persistent state)
2.配置状态 (configuration state)
3.会话状态 (session state)
4.连接状态 (connection state)
5.集群状态 (cluster state)
容器化和持久状态
持久应用的状态需要在应用重启和停用时仍然保留。该类型的状态通常存储在一个冗余的数据库层中,并在数据库层上执行定期备份。
你可以将应用程序和数据库放在同一个容器中,但是最好将它们分开,因为你的应用程序组件更改更频繁。另外,分离数据库以后,多应用实例可以共享数据。
如果你已经使用了外部数据库,不管它们以 service 方式存在,还是部署在不同组的物理或虚拟机上,你都可以保留现有架构,只要把业务逻辑的应用容器化即可。大多数容器管理系统都允许将数据库信息作为配置状态传给应用运行容器(后面会谈到“配置状态”)。
当然,你也可以选择用容器化的数据库。容器化以后,恢复和部署都更快,同时可以享受容器带来的其它好处。这种情况下,你需要考虑下面几个问题:
1 、 数据库如何管理集群化和复制以获取较高的可用性和伸缩性?副本是否有特定的角色?是否能加入新成员,并为其动态分配一个角色?
2 、数据量有多大?添加新节点时,对数据进行 full-sync 是否实际?
3 、基于以上两条,当运行数据库的容器停止时,存在于另一个副本上的数据需要保留吗?如果宿主机停止,数据会保留吗?
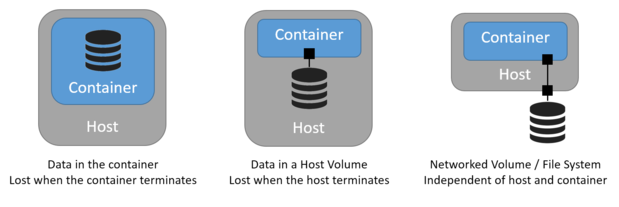
当容器终止时,为了能够保留数据,你将需要使用存储机制来管理容器以外的数据。使用主机 volumes 并把他们映射到容器中很容易做到这一点。
同样,当宿主机终止时,为了能够保留数据,你将需要使用存储机制来管理主机外的数据。大多数的云平台支持共享(网络)文件系统或块存储器( volumes ),可以独立管理并附加或分离到任何主机。假设你的容器编排工具提供生命周期事件来管理存储组件,这也是相当简单的。
但如果数据需要 attach 到特定的容器,怎么处理?很多情况下,这是都是必要的 - 例如我们的一个客户想要管理大量的不能复制的视频内容。如果他们的容器宕掉并在其他主机重启,他们希望相同的数据对容器是可用的。
如果你有许多这样的应用, volume 插件可以简化数据的编排。 从软件分层上来讲, volume 插件在容器引擎下面,作用是协助编排存储。一些 volume 插件只是对 IaaS / CMP 调用进行了一层封装。但有一些插件目的是是提供一组丰富的功能,如 QoS 、分层存储,这些是为了支持企业存储而设计的,也许值得研究。
*** 让我们总结一下 volume 选项:***
-
主机卷:这对于小型数据集能很好地工作,如果数据库支持副本,可以加入一个集群并与其他成员动态同步启动。
-
共享卷或文件系统:当你的数据需要独立于主机以外生存时。这对于大型数据集是一个好的选择。例如当一个新节点加入数据库集群时,你不想执行一个完整的数据同步。
-
Volume 插件:数据需要 attach 到容器中的应用程序,或者你的编排不允许管理外部系统。
容器化与配置状态
应用程序通常需要正确配置非域数据,比如外部服务的 IP 地址,或连接到数据库的凭证。
Heroku 写的 12-factor app 指南中主张在运行时环境中存储配置数据,目前大多数指定 PaaS 解决方案都采用了这种方式。在容器的世界里,大多数配置数据能作为环境变量管理,可以很方便地注入到容器中。
然而,一些需要保密的信息,比如凭证、密码、键和其他机密数据,最好通过其他的安全机制处理,尽量不让秘密数据在主机、网络、或存储上可见。对于这类数据,可以使用 KeyWhiz 、 Vault 等工具管理,容器在初始化时将数据解密。使用支持 key-value 存储的 volume 插件也可以实现同样的目的。
其他类型的状态
我们协助客户容器化应用时,遇到了各种有趣的情况。例如,一个应用程序读取本地 MAC 地址,并用它作为一种方式来唯一地识别自己!显然,如果容器重启,并得到一个不同的 MAC 地址。
幸运的是, Docker 现在允许指定容器的 MAC 地址。对于这种情况,当运行容器时,你需要确保你的编排系统能灵活的指定自定义设置。
总结
本文中,我们讨论了什么是”状态”、你可能遇到的状态类型、以及容器化环境下如何管理。大多数情况,我们都有不止一个选择。因此,虽然容器是短暂的,但应用的”状态”不需要如此!
原文链接: http://www.infoworld.com/article/3106416/cloud-computing/containerizing-stateful-applications.html
目前尚无回复