
这是一个创建于 2935 天前的主题,其中的信息可能已经有所发展或是发生改变。
相信大家对于正则表达式都不陌生,在文本处理中或多或少的都会使用到它。但是,我们在使用 linux 下的文本处理工具如 awk 、 sed 等时,正则表达式的语法貌似还不一样,在 awk 中能正常工作的正则,在 sed 中总是不起作用,这是为什么呢?
这个问题产生的缘由是因为正则表达式不断演变的结果,为了弄清楚这些工具使用的正则语法的不同,我们有必要去简单了解下正则的演变过程,做到知己知彼。当然这个过程本身也是很精彩的,我这里抛砖引玉,希望对大家正确使用正则表达式有所帮助。
诞生期
正则表示式这一概念最早可以追溯到 20 世纪 40 年代的两个神经物理学家 Warren McCulloch 与 Walter Pitts ,他们将神经系统中的神经元描述成小而简单的自动控制元;紧接着,在 50 年代,数学家 1950 年代,数学家Stephen Kleene利用称之为“正则集合”的数学符号来描述此模型,并且建议使用一个简单的概念来表示,于是 regular expressions 就正式登上历史舞台了。插播一下,这个 Kleene 可不是凡人,大家都知道图灵是现代人工智能之父,那图灵的博导是Alonzo Church,提出了 lambda 表达式,而 Church 的老师,就是 Kleene 了。关于 lambda ,之前也写过一篇文章,大家可以参考编程语言的基石—— Lambda calculus。
在接下来的时间里,一直到 60 年代的这二十年里,正则表示式在理论数学领略得到了长足的发展,Robert Constable为数学发烧友们写了一篇总结性文章The Role of Finite Automata in the Development of Modern Computing Theory,由于版权问题,我在网上没找到这篇文章,大家有兴趣的可以参考Basics of Automata Theory。
Ken Thompson 大牛在 1968 年发表了Regular Expression Search Algorithm论文,紧接着 Thompson 根据这篇论文的算法实现了qed, qed 是 unix 上编辑器 ed 的前身。 ed 所支持的正则表示式并不比 qed 的高级,但是 ed 是第一个在非技术圈广泛传播的工具, ed 有一个命令可以展示文本中符合给定正则表达式的行,这个命令是g/Regular Expression/p,在英文中读作“ Global Regular Expression Print ”,由于这个命令非常实用,所以后来有了 grep 、 egrep 这两个命令。
成长期
相比 egrep , grep 只支持很少的元符号,*是支持的(但不能用于分组中),但是+、|与?是不支持的;而且,分组时需要加上反斜线转义,像\( ...\)这样才行,由于 grep 的缺陷性日渐明显, AT&T 的Alfred Aho实在受不了了,于是 egrep 诞生了,这里的 e 表示 extended ,加强版的意思,支持了+、|与?这三个元符号,并且可以在分组中使用*,分组可以直接写成(...),同时用\1,\2...来引用分组。
在 grep 、 egrep 发展的同时, awk 、 lex 、 sed 等程序也开始发展起来,而且每个程序所支持的正则表达式都或多或少的和其他的不一样,这应该算是正则表达式发展的混乱期,因为这些程序在不断的发展过程中,有时新增加的功能因为 bug 原因,在后期的版本中取消了该功能,例如,如果让 grep 支持元符号+的话,那么 grep 就不能表示字符+了,而且 grep 的老用户会对这很反感。
成熟期
这种混乱度情况一直持续到了 1986 年。在 1986 年, POSIX ( Portable Operating System Interface )标准公诸于世, POSIX 制定了不同的操作系统都需要遵守的一套规则,当然,正则表达式也包括其中。
当然,除了 POSIX 标准外,还有一个 Perl 分支,也就是我们现在熟知的 PCRE ,随着 Perl 语言的发展, Perl 语言中的正则表达式功能越来越强悍,为了把 Perl 语言中正则的功能移植到其他语言中, PCRE 就诞生了。现在的编程语言中的正则表达式,大部分都属于 PCRE 这个分支。
下面分别所说这两个分支。
POSIX 标准
POSIX 把正则表达式分为两种( favor ): BRE ( Basic Regular Expressions )与 ERE ( Extended Regular Expressions )。所有的 POSIX 程序可以选择支持其中的一种。具体规范如下表:
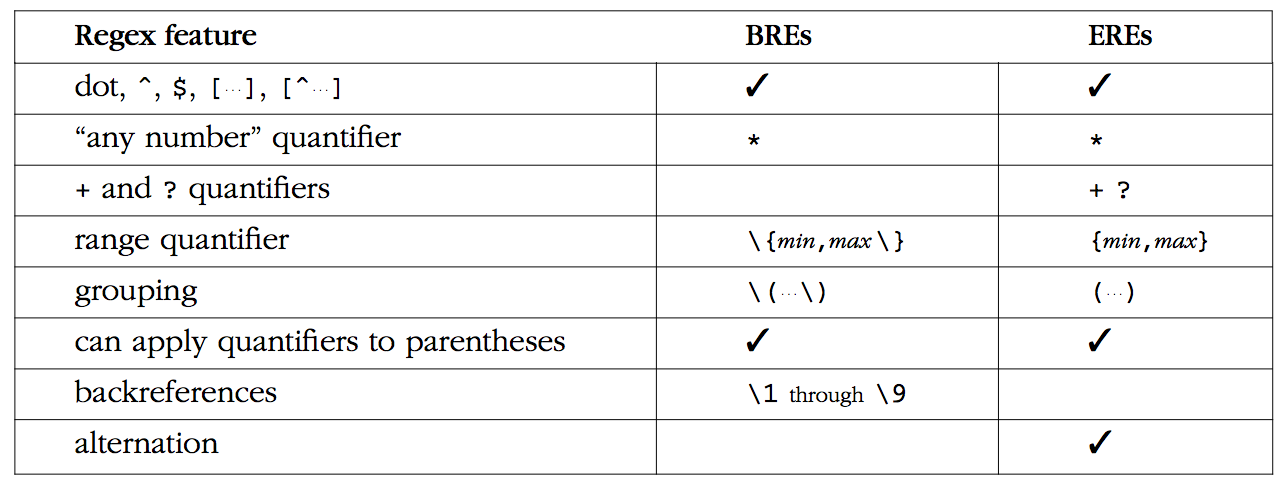
从上图可以看出,有三个空白栏,那么是不是就意味这无法使用该功能了呢?答案是否定的,因为我们现在使用的 linux 发行版,都是集成 GNU 套件的, GNU 是 Gnu's Not Unix 的缩写, GNU 在实现了 POXIS 标准的同时,做了一定的扩展,所以上面空白栏中的功能也能使用。下面一一讲解:
- BRE 如何使用
+、?呢?需要用\+、\? - BRE 如何使用
|呢?需要用\| - ERE 如何使用
\1、\2...\9这样的反引用?和 BRE 一样,就是\1、\2...\9
通过上面总结,可以发现: GNU 中的 ERE 与 BRE 的功能相同,只是语法不同( BRE 需要用\进行转义,才能表示特殊含义)。例如a{1,2},在 ERE 表示的是a或aa,在 BRE 中表示的是a{1,2}这个字符串。为了能够在 Linux 下熟练使用文本处理工具,我们必须知道这些命令支持那种正则表达式。现对常见的命令总结如下:
- 使用 BRE 语法的命令有: grep 、 ed 、 sed 、 vim - 使用 ERE 语法的命令有: egrep 、 awk 、 emacs
当然,这也不是绝对的,比如 sed 通过-r 选项就可以使用 ERE 了,大家到时自己 man 一下就可以了。
还值得一提的是 POSIX 还定义了一些 shorthand ,具体如下:
- [:alnum:]
- [:alpha:]
- [:cntrl:]
- [:digit:]
- [:graph:]
- [:lower:]
- [:print:]
- [:punct:]
- [:space:]
- [:upper:]
- [:xdigit:]
在使用这些 shorthand 时有一个约束:必须在[]中使用,也就是说如果像匹配 0-9 的数字,需要这么写[[:alnum:]],取反就是[^[:alnum:]]。 shorhand 在 BRE 与 EBE 中的用法相同。
如果你对 sed 、 awk 比较熟悉,你会发现我们平常在变成语言中用的\d、\w在这些命令中不能用,原因很简单,因为 POSIX 规范根本没有定义这些 shorthand ,这些是由下面将要说的 PCRE 中定义的。
PCRE 标准
Perl 语言第一版是由Larry Wall发布于 1987 年 12 月, Perl 在发布之初,就因其强大的功能而一票走红, Perl 的定位目标就是“天天要使用的工具”。 Perl 比较显诸特征之一是与 sed 与 awk 兼容,这造就了 Perl 成为第一个通用性脚本语言。
随着 Perl 的不断发展,其支持的正则表达式的功能也越来越强大。其中影响较大的是于 1994 年 10 月发布的 Perl 5 ,其增加了很多特性,比如 non-capturing parentheses 、 lazy quantifiers 、 look-ahead 、元符号\G 等等。
正好这时也是 WWW 兴起的时候,而 Perl 就是为了文本处理而发明的,所有 Perl 基本上成了 web 开发的首选语言。 Perl 语言应用是如此广泛,以至于其他语言开始移植 Perl ,最终 Perl compatible (兼容)的 PCRE 诞生了,这其中包括了 Tcl, Python, Microsoft ’ s .NET , Ruby, PHP, C/C++, Java 等等。
前面说了 shorthand 在 POSIX 与 PCRE 是不同的, PCRE 中我们常用的有如下这些:
\w表示[a-zA-Z]\W表示[^a-zA-Z]\s表示[ \t\r\n\f]\S表示[^ \t\r\n\f]\d表示[1-9]\D表示[^1-9]\<表示一个单词的起始\>表示一个单词的结尾
关于 shorthand 在两种标准的比较,更多可参考Wikipedia
总结
我相信大家最初接触正则表达式( RE )这东西,都是在某个语言中,像 Java 、 Python 等,其实这些语言的正则表达式都是基于 PCRE 标准的。 而 Linux 下使用各种处理文本的命令,是继承自 POSIX 标准,不过是由 GNU 扩展后的而已。
大家如果对 sed 、 awk 命令不熟悉,可以参考耗子叔下面的两篇文章:
参考
- GNU Regular Expression Extensions
- POSIX Bracket Expressions
- Regular_expression
- Linux/Unix 工具与正则表达式的 POSIX 规范
文章原地址,欢迎大家关注我的公众号,获取更多技术文章
 |
1
yuuko 2016-11-10 11:08:40 +08:00
不错
|
 |
2
fy 2016-11-10 11:47:37 +08:00
|
 |
3
Vicer 2016-11-10 14:05:50 +08:00 via Android
涨姿势
|