
这是一个创建于 2872 天前的主题,其中的信息可能已经有所发展或是发生改变。
本文来自 CSDN 《程序员》 2017 年 2 月的封面报道。 对于一个从零开始的数据库来说:选择什么语言,整体架构怎么做,要不要开源,如何去测试…太多的问题需要去考量。 在本篇文章中, PingCAP 联合创始人兼 CTO 黄东旭对 TiDB 的开发历程进行了详细简介,为大家还原 TiDB 的架构演进全过程。
在大约两年前,我有一次做 MySQL 分库分表和中间件的经历,那时在中间件里做 sharding ,把 16 个节点的 MySQL 扩到 32 节点,差不多要提前一个月做演练,再用一个礼拜来上线。我就在想,能不能有一个数据库可以让我们不再想分库分表这些东西?当时我们也刚刚做完 Codis ,觉得分布式是个比较合适的解决方案。另外我一直在关注学术圈关于分布式数据库的最新进展,有看到谷歌在 2013 年发的 Spanner 和 F1 的论文,所以决定干脆就重新开始写一个数据库,从根本上解决 MySQL 扩展性的问题。
而决定之后发现面对的问题非常复杂:选择什么语言,整个架构怎么做,到底要不要开源……做基础软件有一个很重要的事情:写出来并不难,难的是你怎么保证这个东西写对了。尤其是对于业务方,他们所有的业务正确性是构建在基础软件的正确性上。所以,对于分布式系统来说,什么是写对了,怎么去测试,这都是很重要的问题。关于这些我想了很久。
一开始总是要起步的。当时就决定冷静一下,先确定一个目标:解决 MySQL 的问题。 MySQL 是单机型数据库,它没有办法做全扩展,我们选择 MySQL 兼容,首先选择在协议和语法层面的兼容,因为已有的社区里边很多的海量的测试。第二点是用户的迁移成本,能让用户迁移得很顺畅。第三是因为万事开头难,必须得有一个明确的目标,选定一个目标去做,对开发人员来说心理的压力最小。确定目标以后,我们 3 个人的创始团队从原来的公司出来,拿了一笔比较大的风险投资,开始正式做这件事情。
兼容 MySQL 最简单的方案,就是直接用 MySQL 。为了让这个东西尽快地做起来,我们一开始做了一个最简单的版本,复用 MySQL 前端 代码,做一个分布式的存储引擎就可以了,这个事情想想还是蛮简单的,所以非常乐观,觉得这个战略很完美。
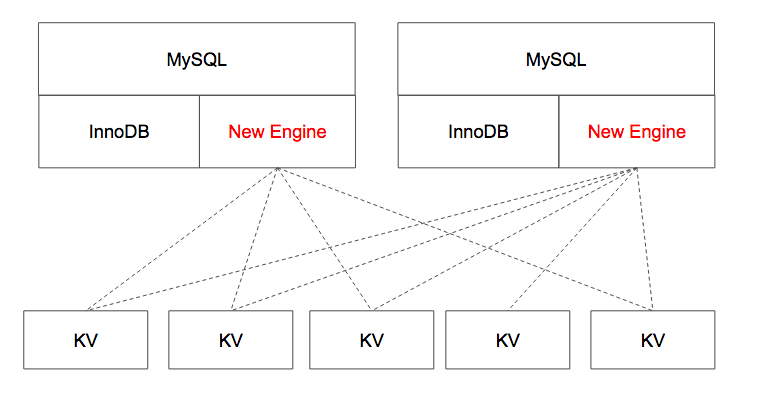 上图是我在 2015 年 4 月份用六个礼拜完成的第一个版本的框架,但是后来没好意思开源出来,虽然能跑,但是在性能上完全无法接受。我就想这个东西为什么这么慢?一步一步去看每一层,就想动手改,但是发现工程量巨大,比如 MySQL 的 SQL 优化器, 事务模型等等,完全没有办法下手。就像这个架构图里看到的,因为在 MySQL Engine 这一层,我们能做的事情太少了,所以就没有办法。
上图是我在 2015 年 4 月份用六个礼拜完成的第一个版本的框架,但是后来没好意思开源出来,虽然能跑,但是在性能上完全无法接受。我就想这个东西为什么这么慢?一步一步去看每一层,就想动手改,但是发现工程量巨大,比如 MySQL 的 SQL 优化器, 事务模型等等,完全没有办法下手。就像这个架构图里看到的,因为在 MySQL Engine 这一层,我们能做的事情太少了,所以就没有办法。
第一版实验到此宣告失败,现在看起来写 SQL parser 和优化器等这些已经是绕不开了,我们索性决定从头开始写,唯一给我安慰的就是终于可以使用我们最爱的编程语言了,就是 Go 。
我们跟其他做这种软件的工程师的思路相反,选择了从上往下写,先写最顶层的 SQL 的接口 SQL Layer ,我要保证这个东西长得跟 MySQL 一模一样,包括网络协议和语法层。从 TiDB 网络协议、 SQL 的语法解析器、到 SQL 的优化器、执行器等基本从上到下写了一遍。这个阶段持续了大概三个月左右。从这个阶段开始,我们慢慢摸索出了几个实践中深有体会的开发哲学。
第一,所有计算机科学里面的问题都可以把它不停地抽象,抽象到另外一个层次上去解决。
我们完成了架构 0.2 ,此时 TiDB 只有一个 SQL 解析器,完全不能存数据,因为底下的存储引擎根本没有实现。我想要保证这个数据库是对的,要先保证 SQL Layer 是对的,让它可以完整的跑 MySQL 的 test 。至于底下的存储我可以实现个假的或者内存里先存着,先保证我的 SQL 正常运转起来就可以了。
其实在苦哈哈的写 TiDB 的 SQL Parser 的时候我们还做了很多事情,不管是 MySQL 的 unittests , SQL logic tests , ORM tests 等,把它的测试全都收集下来,到现在大概有一千万个集成测试用例。我们还做了一个事情,就是把存储引擎这个概念抽象成很薄的几个接口,使得它去接入一个 KV engine 。绝大多数的 KV engine 非常多,比如 LevelDB , RocksDB ,接口的语义都是非常明确的。
几个月过去了,团队也大约有了十几个人,因为在每一层我都非常严格地要求我们团队用接口来划分,使得每一个层次上的工作都是可以并行,这对于整个项目的推进是非常有利的事情。
大概去年九月份,历史上第一个不能用来存数据的数据库——没有存储引擎的第一版 TiDB 开源了,放在 HackerNews 非常受欢迎,还被推荐到了首页。
第二, Talk is cheap , show me the tests 。
做基础软件 test 是比 code 更重要的事情。比如你提了一个 Feature ,我到底是合并还是不合,不能直接判断,需要看到你的 test 。我们现在在 GitHub 上运营 TiDB ,一个新的提交如果让整个项目的代码测试的覆盖率下降了,我是不允许你的代码合并到主干分支的,非常严格。构建一个数据库最难的并不是把它写出来,而是证明它是对的,尤其是分布式系统的测试要比单机的测试要更加困难。因为在分布式系统里面每一个节点都可能 crash ,每一个网络的延迟可能是飘忽不定的,各种各样的异常情况都会发生。我们在做整个数据库的时候,第一步是完成 SQL Layer ,第二步是把每个 IO ,每个集群的节点交互行为全都抽象成为一个接口,使得我们可以回放整个包括 TCP/IP 包的接收顺序。一旦发现 bug ,就把它重放到单元测试里面重现。不管是新的开发者或者新的模块加入,是无法相信“人”的,只相信机器。我只相信 strong test 才能不断的保证项目在可以控制的范围之内。
后来做了一个架构 0.5 ,因为已经有了 SQL 层, SQL 层跟存储层基本上做了完全分离,终于可以像最初的 0.1 那样,我可以接一个分布式引擎上去,当时我们接了 HBase 。 HBase 是阶段性的战略选型,因为我们想既然我的 SQL Layer 写的足够稳定,那么我们先接一个分布式的引擎上去,但是我又不能在架构中引入太多不确定的变量,于是就挑选了一个在市面上能找到的,我认为最稳定的分布式引擎,先接上去看整个系统到底能不能跑起来。结果还可以,能够跑起来,但是我们的要求会更高,所以之后我们就把 HBase 扔掉了。接 HBase 这个事情标志着我们上层 SQL Layer 跟我们接口的抽象已经足够稳定,我们的 test 已经足够健壮,能让我们往下一步步去做分布式的东西。
这个架构大概是这样:
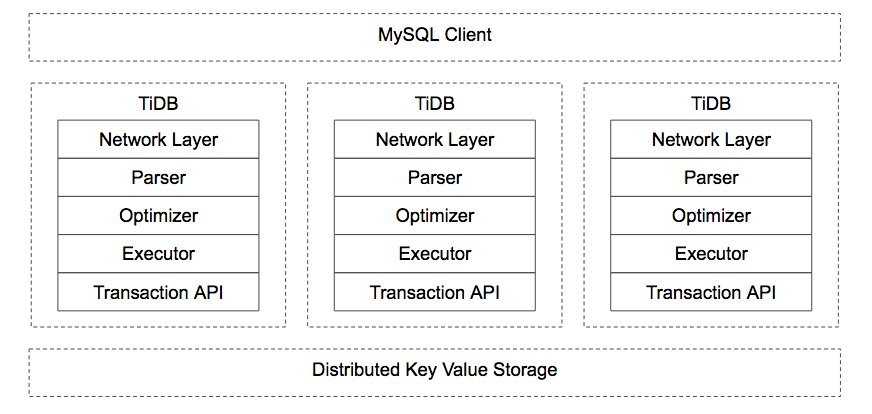
上层是 MySQL 业务层 Client ,你可以用任意的 MySQL 的客户端去连接它,如果数据量大的话,你不需要再去分库分表,就把它当成无穷大的 MySQL 用就好,这个用户体验很好。因为 TiDB 是一个无状态的设计,它并不存储数据,所以你可以部署无数多个 TiDB 负载均衡。底层一开始是个 HBase ,那时候是 11 月,至此距离创业半年过去了。
因为有海量的 Test 保证,让整个设计的过程没有太过困难。不过这里涉及一个问题:我们在做技术选型的时候,如果在有很大自由度的前提下,怎么去控制发挥欲望和膨胀的野心?你的敌人并不是预算,而是复杂度。你怎么控制每一层的复杂度是非常重要的,特别是对于一个架构师来说,所有的工作都是在去规避复杂度,提升开发效率和稳定性。
当时我们选择了一个非常小众的编程语言就是 Rust 。首先它是一个 high performance 的编程语言,它没有 GC ,也没有 runtime ,很多的创新是做在了编译器这一层,最大的特点就是安全、安全和安全,我认为它是更现代的 C++,不过 C++ 最大的问题是如果用不熟容易把自己的手脚砍断。当时我选 Rust 以后,很多朋友问我你为什么去选择它。说实话最开始我是很怕的,因为这个语言毕竟是一个新的比较小众的语言, community 也没那么大,但这是当时对于我们团队的状况来说是最优选择。我们就用 Rust 写起来,结果一不小心 TiKV 成为了 Rust 社区最大的开源项目之一。因为我们在 Rust 很早期的时候就开始用了, Rust 官方也一直在找我们来分享 Rust 的使用经验,我们也很热心的去拥抱 Rust community 。 Rust 社区每周的 weekly 里面有一个固定的专栏叫做 “ This week in TiKV ” ,就是为我们打造的 :)
2015 年的冬天我们是在纠结中度过的。一是用最新的编程语言 Rust , 大家之前都没有接触过;第二就是,我们想要的“弹性扩展、真正的高可用、高性能、强一致”这四点要求,每一个都非常困难。
怎么办?只能去拥抱社区,不要自己去做所有的事情,一是人数有限,第二是复用是个很好的习惯,既然别人都已经干过这些事情,就不要再去重复性的工作。我们要做一个真正高可用的数据库,把高可用的分布式存储找了一圈发现 Etcd , Etcd 背后算法叫 Raft 这是个一致性算法等价于 Paxos 。这个算法目前来说最稳定地实现就是 Etcd 里的 Raft 。而且 Etcd 是真正在生产环境中被大量认证过的 Raft 的实现。我仔细看过 Etcd 的源码,每个状态的切换都抽象成接口,我们测试是可以脱离整个网络、脱离整个 IO 、脱离整个硬件的环境去构建的。我觉得这个思路非常赞,这也是为什么 CoreOS 的 Etcd 包括像 k8s 背后的元信息存储也用的是它,质量非常高,性能非常好。但是 Etcd 有一个问题是它是 GO 写的,我们已经决定去用 Rust 开发底层存储的数据库。如果用类似 paxos 这种算法,我不相信除了 Google Chubby 以外的公司有能力把它写对。但是 Raft 不一样,虽然它也很难,但是毕竟它是可以实现的东西,所以我们为了它的质量,加速我们开发的进度,我们做了一件比较疯狂的事情,就是我们把 Etcd 的 Raft 状态机的每一行代码, line by line 的翻译成了 Rust 。而我们第一个转的就是所有 Etcd 本身的测试用例。我们写一模一样的 test ,保证这个东西我们 port 的过程是没有问题的。
TiDB 底层的存储引擎一开始是不能存数据的,那现在是时候要选一个真正的 Storage engine ,我们觉得这个事情是一个巨坑。本地存储引擎让一个小团队去写的话基本不现实,我们就从最底层选择了 RocksDB 。 RocksDB 大家可以认为是一个单机的 key-value engine ,前身其实是 LevelDB ,是 Google 在 2011 年左右开源的 key-value 的存储引擎。 RocksDB 的背后结构是 LSM Tree ,是一个对写非常友好、同时在你的机器内存比较大的时候它的读性能会非常好的数据结构 。存储引擎还有一个很重要的工作就是,需要根据你机器的性能去做针对性的调优,大家会看到像 MySQL 调优都快变成黑魔法一样的东西, RocksDB 也是一个调优能写本书的存在。大家可以看到,新一代的分布式数据库存储引擎大家都会选择 RocksDB ,我觉得这是大势所趋。
从 15 年的冬天开始,我们苦逼哈哈的写了 5 个月的代码,用 Rust 去写,到 2016 年 4 月 1 日 TiKV 终于开源了。
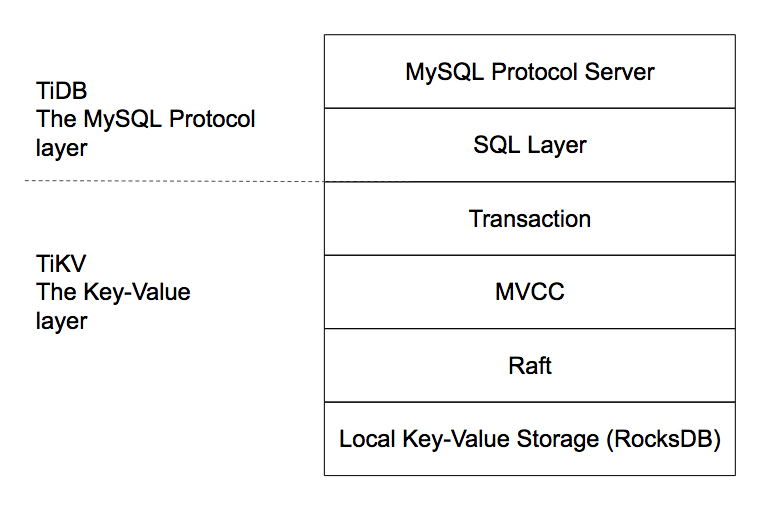
从上图能看到,最底层是 RocksDB ,上面的分布式这一层是用 Raft ,这两层虽然是我们写的,但是质量上是我们社区的盟友帮我们保证的。在 Raft 之上是 MVCC ,从这里往上,就都是我们自己来写的了。所以 TiKV 终于是一个可以实现弹性扩展、支持 ACID 事务、全局一致性,跨数据中心高可用的存储引擎了,而且性能还非常的棒。因为我没有在底下去接一个像 HDFS 的文件系统。
其实从开源到现在,我们一直在做 TiKV 的性能调优、稳定性等很多的工作,但是从架构上来看,这个架构我觉得至少在未来的五年之内,不会再有很大的变化。我一直在强调的点就是:复杂性才是你最大的敌人,我宁可是以不变应万变的姿势去应对未来突变的需求。还好,数据库这个东西的需求变化也没太多。
第三, Where there ’ s a metric there ’ s a way 。
再说说 Metrices 。对架构师而言一个很重要的工作就是查看系统中有哪些 block 的点,挨个解决掉这些问题。我们发现在数据库领域,有很多很多点如果能予以解决的话,性能会上去十倍。我有一个观点,所有的东西,只要有 Metrices ,能被监控,这个东西就能被解决。 也就是:“ Where there ’ s a metric there ’ s a way ”。 一旦能重复观察性能的平衡点,性能问题是最好解决的问题,但是写对是最难的问题。
一般来说大家都在公司内部自己去审 Metrics ,还有监控工具。对于我们小团队来说,或者说是一个拥抱社区的团队来说,这基本上是一个得不偿失的事情。因为你费好多劲去写一个,还不如社区里面写得好,这很麻烦。所以,我们在数据库里面内嵌了 Prometheus 和 Grafana 。 Prometheus 现在在硅谷太火了,它其实是一个分布式的时序数据库,但是它很适用于日志搜集和性能调优,它做得更完美的地方是它提供 DSL 去用于查询提供监控的报警,包括你可以写报警的规则。它没有一个好看的 Dashboard ,这时社区里面另外一个哥们就出来,说我要去给你做一个很好看的界面,这个项目就是 Grafana 。 Grafana 是一个可视化的 dashboard ,它能让每一次 dashboard 排布的位置、类型、样式、大小、宽度都是可以自定义的。而且整个 Metrics 收集 Prometheus 提供了两种模式,一种是 push 的模式,一种是 pull 的模式。 对于收集监控的代码性能影响很小。
最后想补充的问题,第一就是工具。对于一个互联网出身的团队来说,其实工具是我们非常重视的一个点,可以最小化业务的迁移成本。我觉得很多在大公司做重构,或者做基础软件的工程师,最好的方式就是润物细无声。你完全不知道我在做底层的重构就莫名地重构完了,这是最完美的状态。比如我之前做 Codis ,我的要求是如果用户现在在用 Twemproxy ,他迁到新的方案上必须要一行代码都没有改,你甚至完全不知道我在做迁移,这才是最好的,我认为这应该是所有做基础设施团队的自我修养。
第二就是不要意外。比如说,你在做一个数据库,你号称跟 MySQL 一模一样,那么你展现出来任何跟 MySQL 不一样的东西都会让用户吓一跳,而且这是很重要的一个开发原则。
第三就是悲观预设。永远都会有各种各样的恶心事情和异常的状况发生,其实这是作为分布式系统开发工程师每天都要对自己说的话。业务的数据是重于泰山的,但是任何的基础设施都是会挂的,你的网线可能会断,整个数据中心可能会 shut down ……你要预设你的数据库是一定会丢数据的,这个时候你的数据库设计才会更好。如何保护自己如何保护业务,我们做了一些神奇的工具,比如像 syncer ,这个东西就是把 TiDB cluster 作为一个 假的 slave 接到 MySQL 上,业务在上面跑 MySQL ,后面存起来其实是个集群。另外还做了一个比较变态的事情,就是反向。我们顶在业务上面,下面可以接到 MySQL 。 MySQL 可以做 TiDB 的 slave , TiDB 可以做 MySQL 的 slave 。这个功能对于业务来说是非常惊喜的。有的客户一开始想用 TiDB 但是有点害怕,我说没关系,你在后面接个从,然后你在从上面去查询。比如你原来一个 SQL 跑了 20 分钟,现在我能让你跑到 10 秒以内;或者你跑了大概半年都一点数据没丢,系统非常稳定,再切成主的业务代码中更改。
一个架构师总是要去想一些未来十年会发生什么。有一个名词 Cloud-Native ,我是认为一切的东西在未来都会跑在云端,如何针对云上这个环境去设计基础软件?数据库设计一个很重要的原则是,数据一旦发生了宕机它能够自动修复和均衡数据,人在里边给这些集群加机器就行了,整个集群一定要能够有自己的思考。未来怎么针对 Cloud 做基础架构,这是一个需要去思考的问题。

