
这是一个创建于 2902 天前的主题,其中的信息可能已经有所发展或是发生改变。
大概去年的时候 10 月份的时候,看到了 v 友的这篇帖子:一个简单的网文推荐系统,解决书荒。
这位 v 友当时没有给出源码地址,于是我就打算自己也实现一个。不过,由于算法复杂度太高以及自己学习的很浅(现在学习的也不深),也没有想到好的办法就暂时搁在了一边。拖到了最近,使用了局部敏感哈希(LSH)的方法降低了最近邻搜索的时间复杂度,也算简单的把它实现了,推荐结果算是勉强可以看了,效果如下图:
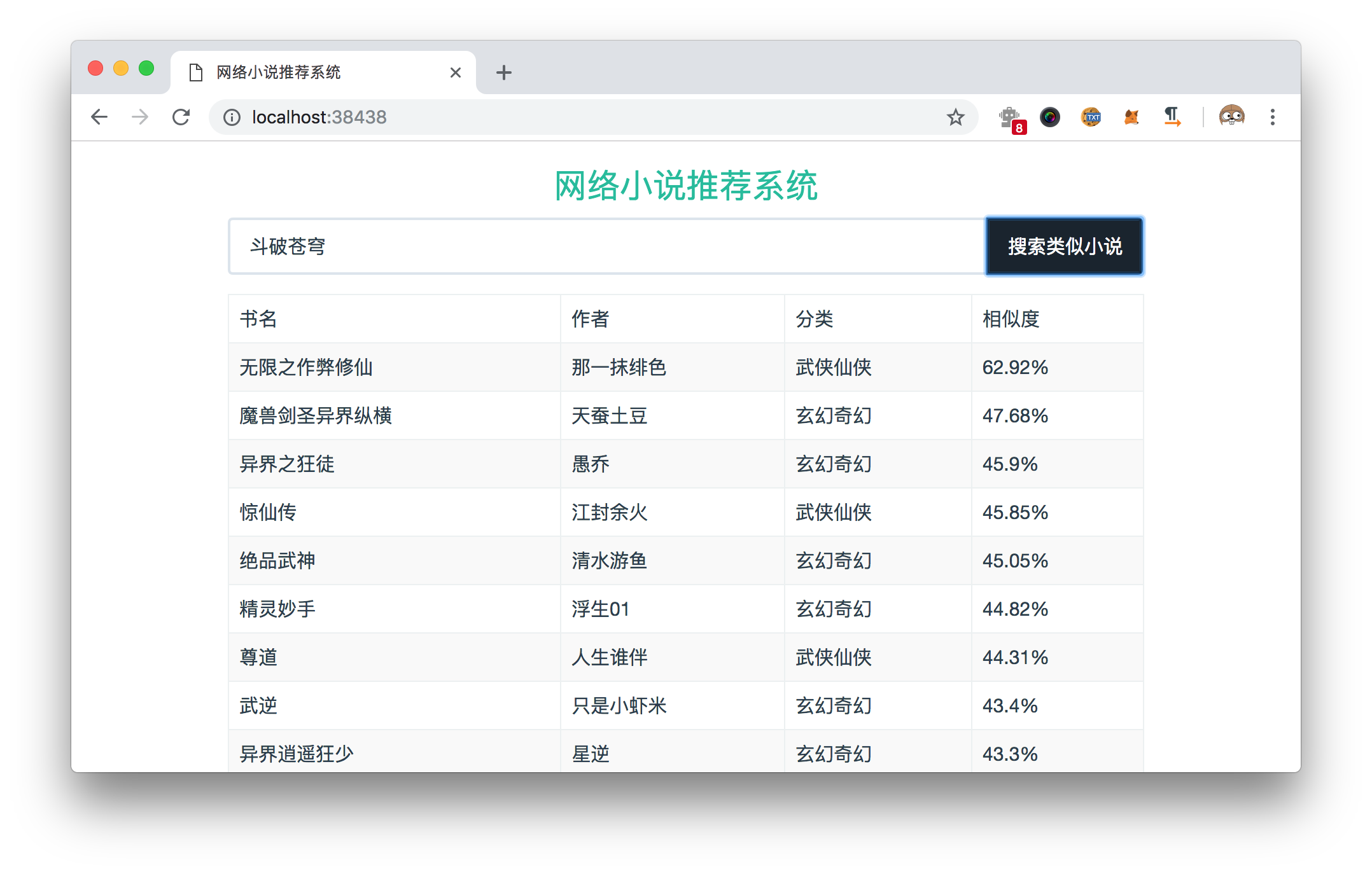
算法流程如下:
- 1 、爬取小说
- 2 、小说分词
- 3 、 TF-IDF 向量化
- 4 、最近邻搜索
由于小说爬取的比较杂乱,什么女频的男频的都有,所以有些推荐结果可能有些诡异,另外使用局部敏感哈希来搜索也会影响推荐的准确度,下面贴出链接希望 v 友能给出些改善建议。
推荐测试地址:http://tx.kalen.site:38438/
github 链接: https://github.com/nladuo/novelRS
 |
1
coderluan 2017-04-24 14:03:49 +08:00
试了一下,楼主你其实是在骗我们吧,你这个就是彻头彻尾随机推荐吧...
|
 |
2
chengfu 2017-04-24 14:05:30 +08:00
好像很厉害的样子,既然是纯搜索功能,能不能做成一个 wp 可以使用的插件呢,集成到 wp 还是不错的说;另外,相似度的准确性怎么算的,有多高(不是说百分比数据,而是“相似度”这个参数本身)
|
|
3
coderluan 2017-04-24 14:10:08 +08:00
说正经的,我建议楼主可以爬优书网(龙空)的数据,然后按分类和评分高低推荐。
|
 |
4
nladuo OP @chengfu 相似度就是余弦相似度,把两本小说分词,转换成 Bag-of-Words 模型,通过两个向量的点乘再除以两个向量的模来计算相似度。
|
 |
5
enenaaa 2017-04-24 14:14:47 +08:00
不如爬优书网的书单, 以用户和书单收藏来推荐。
|
 |
6
v2pro 2017-04-24 14:15:13 +08:00 LDA 或者 LSA 效果应该比 hash 好。。。
如果是爬的小说,带有原来的类别或者标签就更好了,带标签的 LDA 效果更好些。。。 |
 |
7
wolfan 2017-04-24 14:16:56 +08:00 via Android
看书不如写书,写书不如神精网络生成,以后编剧什么的就不存在了。
|
|
8
nladuo OP @coderluan 谢谢建议,可能是由于书的质量原因吧,感觉 YY 小说的推荐结果稍微靠谱一些,不知道是不是我爬的数据的原因。像盘龙、星辰变这样的图书结果确实是不太好。
|
 |
13
lcatt 2017-04-24 15:07:23 +08:00
很多小说都没有。。。。
|
|
15
lcatt 2017-04-24 15:12:15 +08:00
我搜《王牌进化》,结果出来的都是一些乱七八糟的推荐。。。理想中应该是同一作者的《最终进化》,然后是同一类别的其他作者热门书籍比如《死亡名单》《无限进化》等等。。。
|
 |
16
whale 2017-04-24 15:44:05 +08:00
目前在看的十几本小说都显示未找到!只能查全本?
|
 |
17
wzha2008 2017-04-24 17:03:11 +08:00
小说推荐还是用协同过滤更好一些
|
 |
18
Sn0wM4n 2017-04-24 17:50:58 +08:00
搜了几部都未找到,看来我口味独特
|
 |
19
xiaome 2017-04-24 18:05:35 +08:00
可能,也许,大概,应该是数据不够? |
 |
20
smdx 2017-04-24 18:23:37 +08:00 via iPhone
程序员会看小说吗
|
|
21
smdx 2017-04-24 18:27:03 +08:00 via iPhone
我总觉得程序员没有人文素养,说话和天涯得人,简直一个是油,一个是水,区别太大了
|
 |
22
tumbzzc 2017-04-24 19:25:17 +08:00
图中的搜索完全和结果没有关联吧?
|

 |
24
MyFaith 2017-04-25 09:55:52 +08:00
楼主头像和代码不太匹配呀
|
 |
25
nicoljiang 2017-04-25 16:32:55 +08:00
这个推荐思路本身我觉得就有问题。
小说的相关度是靠题材、背景、设定、情节等来判断的,其中最复杂的是设定。 用关键词的方式来做,可预见的就不会很准。 最近向量分析工具被玩坏了~ |