
这是一个创建于 2798 天前的主题,其中的信息可能已经有所发展或是发生改变。
本文是我司 CTO 黄东旭同学在 DTCC2017 上的《 When TiDB Meets Kubernetes 》演讲实录,主要分享了关于 TiDB 与 Kubernetes 整合的一些工作。文章较长,且干货满满。
 ###以下为演讲实录:
###以下为演讲实录:
今天给大家带来的分享是关于 TiDB 与 Kubernetes 整合的一些工作。在讲之前,想了解一下,在场的各位有听说过 Kubernetes 的同学举个手;听说过 TiDB 的举个手,非常好。因为我也是 DTCC 的常客了,前几年来讲的时候基本上没有人听说过 TiDB,随着这个项目越来越成熟,很欣慰,有一些社区的小伙伴已经用起来了。
我先简单介绍一下我自己。我是 PingCAP 的联合创始人兼 CTO,也是 TiDB 项目的码农 ,之前一直也是在做 Infrastructure 和分布式系统相关的一些工作。同时也是特别喜欢开源,基本上做的所有东西都是开源,包括像 Codis、TiDB、TiKV 这些项目。比较喜欢的编程语言有 GO、Rust、Python。
对于今天的话题,如果说在 40 分钟之内要去完整的介绍怎么做一个数据库或者说怎么去做一个集成调度的系统,我觉得是不太可能的。
所以今天这个 Talk 我主要会分享 TiDB 作为一个分布式关系型数据库与云整合的经验,以及我们遇到的一些问题,来帮大家在遇到相似的问题时提供一个解决思路。大家其实在存储系统上可以把 TiDB 换成任何东西,然后对于在 Kubernetes 上的融合,我觉得都会有一些启发的意义。
首先想强调的是,Cloud 才是未来。现场做一个小调研:有在线上生产环境中,正使用 Kubernetes 或者 Mesos 这样的容器化管理方案的同学吗?好,一个两个三个。
我相信,如果在三到五年以后,再去问这个问题,应该是至少一半的同学会举手。因为其实在可见的未来,数据量是一直在膨胀,业务会越来越复杂。包括现在很多微服务的这种思想,当你的业务比较大的时候,会把整个服务拆成非常细的模块,然后在众多的模块的拆分之下,怎么去高效的运维你的分布式集群,其实靠 SRE 或者运维人员手动去管理各个微服务或者说各个的系统,其实是不太现实的。
但是大家也都知道,对于这种无状态的业务,比如像 Application 应用层,其实它并不会真正的存储数据,状态一般都持久化到数据库或者缓存中,所以它基本是无状态的。所以其实一直以来大家在使用容器化遇到的第一个问题就是,有状态的服务,特别是数据库或者分布式存储系统,怎么去运维。比如说我在 Docker 里面写的数据,这个容器销毁它直接就挂了,它其实是很难去做这种数据层面上的东西。
然后另外一方面就是数据库的运维,不管是放在云上做还是 DBA 自己在物理机上做,一样的痛苦,所以怎样去设计一个面向云的环境下、或者说在分布式系统上去做数据库。其实这也是在做 TiDB 的过程中我一直在想的。TiDB 这个项目一开始的设计就是:它一定会放在云上去运转。
上图是 Amazon 在它的云上选择创建一个数据库实例的一个界面,大家不用看具体的字是什么,只是给大家感受下:就是说我作为一个业务的开发,我要去存储一个数据,启用一个 PG 或者 MySQL 的数据库,我还要去关心这么多个选项,或者说我一定要去关心我的这个物理机到底是什么样的情况:磁盘有多大,什么机型,各式各样的配置等。因为毕竟不是所有人都是专业的 DBA,也不是所有人都是操作系统的专家,当时看到这个页面的时候,基本上业务开发可能是一脸懵逼的状态。
现在所有人都跟你说,我的系统是一个分布式系统,在广告里写的非常漂亮。现在哪一个数据库说自己不是分布式的,那基本上只能是落后于时代。但是,大家有没有想过,现在所有的这些分布式系统、分布式数据库,运维起来都是非常痛苦,没有办法去很好的把它用好。
以 Hadoop 为例,现在 setup 一个 Hadoop 的集群竟然能成为一个生意,这个生意还让两个创业公司都上市了,一个是 Cloudera,一个是 Hortonworks。其实严格来说,他们只是做 Hadoop 运维的创业公司。然后还有无数的公司在做 Spark 的维护、Spark 的管理。各种各样的数据库运维公司,靠这个都过的非常好。
这个其实在我看来是非常不正常的,因为大家想,如果你去运维一两台机器那没有问题,我写一个脚本,轻轻松松的就可以搞定;然后三五十台机器,也还行,招一个 OPs 或者说招一个 DBA,还是可以人工的管理。
但是如果是在 100 台、1000 台甚至 10000 台规模之上,机器的故障会是每天每夜无时无刻都发生的,网络的抖动,磁盘 IO 的异常,一直都在发生,靠人是没有办法做的。总的来说就是,当你去运维一个 single node 的系统时,基本上没有什么难度;但是如果要去运维一个特别大的 P2P 的 distributed system,尤其是节点数特别多的时候,你的状态和维护的成本就变得非常高。
之前我做过一个项目叫 Codis,可能有很多同学听说过,也可能很多同学已经用在生产环境之中。还有另外一个不是我做的项目,就是官方的 Redis Cluster。当时很多社区里面的 Redis Cluster 的粉丝一直喷我,说 Codis 的配置怎么这么复杂,一点都不好用,组件怎么这么多。现在这个事情又在重演。
很多系统做成了 P2P 的模型了以后,组件很少部署很方便,但是真正在去运维它的时候,比如说要去做一个滚动升级或者我想清楚的知道整个集群的数据分布和各个组件的状态,又或者说是我的分布式逻辑出了个 bug,但是我的存储层没事,需要做个热更新这个时候,p2p 系统的运维复杂度就凸显了。Codis 它其实有一个 Proxy,一个存储层,这两层在逻辑上其实是分离的;但是 Redis Cluster,每一个节点既是它的分布式调度模块,同时又是它的数据存储模块,这时候整个系统架构是混在一起的,对于运维的同学来说这就是一个恶梦。
如果我想清楚的知道我的数据到底是在哪几台机器上,比如说这块数据特别热我想把它挪走,这时候像在 Redis Cluster 这种纯 P2P 的系统里面是很难得到它的当前状态。所以这也是影响了我后来一系列的系统设计的想法,所以 operation 是一个非常困难的事情,在一个特别大的分布式系统里,是一个非常困难的事情。
因为你的服务和组件特别多,不同的组件,不同的模块,然后再加上一个分布式系统里边特别不稳定的网络状态,使得各种各样的异常情况,人是没有办法去掌控的。
还好,Google 是一个非常伟大的公司,像 TiDB 整个模型大家也知道是参考了 Google Spanner / F1。Kubernetes 背后的系统的前身就是 Google 的 Borg。
Borg 其实是 Google 内部一直在用着的大规模的集群调度器。Borg 这个单词就是星际迷航里面的一个角色,相当于它作为整个集群的一个大脑来去控制集群的业务的分布跟数据的均衡,所以 Google 给我们带来了 Kubernetes 这个项目。
Kubernetes 主要的工作就是一个面向 Container 的集群管理的服务。它同时会去做服务编排,Auto deployment、Auto scaling、Auto healing,你的整个集群的这些服务的生命周期的管理,然后故障的转移、扩容...你可以认为它是一个集群的操作系统。大家可能认为操作系统就是单机上的一个概念,但是如果放到一个大规模的分布式系统里面,你有无数的 CPU 资源,无数的内存,无数的磁盘资源,怎么高效的去把你的服务在这些海量的资源上进行合理的分配,这个就是 Kubernetes 干的事情。
TiDB 大家也都非常熟悉了,我简单介绍一下吧。
我们做 TiDB 的目标就是,希望构建一个完全弹性的,用户不需要去知道数据的分布信息,也不需要去做手工的数据分片,可以把它当做一个单机的数据库、MySQL 的数据库在用,但是它背后是一个高度弹性和智能的分布式的数据库。对业务层你不需要再去想分库分表,也不需要再去想热点的 balance 这种事情。它支持百分之百的 OLTP 的功能,可以支持跨行事务,像 MySQL 一样:我开始一个 transaction,然后写写写,最后 commit,全成功或者全失败,没有第三种可能 。支持事务的前提之下还支持 80% 的 OLAP。
所以 TiDB 是非常适合去做这种一边有实时写入,一边有复杂 Join 和实时分析的场景,它的 SQL 优化器其实也有从 Spark SQL 里面学到了很多东西。
当然对外的接口是完整的 MySQL 的接口,你可以直接用 MySQL 的客户端就连上了。另外,背后它支持高可用。因为底层的复制协议并不是通过像这种主从模型去做数据冗余的,而是用 Raft,Raft 跟 multi-paxos 是比较接近的,都是基于选举的算法。
在遇到 MySQL 的扩展性问题的时候,大家过去只能一脸懵逼,然后反回来去拆库拆表,或者去用 MyCat 或者依托 MySQL 的中间件去做 sharding。其实这对于业务层来说,侵入性非常大,所以 TiDB 的初衷就是解决这个问题,但是它没有用任何一行 MySQL 的代码。
###TiDB 大概是这样一个架构:
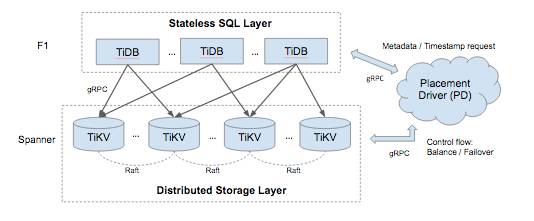
TiDB 其实也是由很多的组件组成,它并不是一个纯粹的 P2P 系统,如果看这个架构其实非常像 Codis。
今天的主题是说我们怎么在 Kubernetes 上去做 cluster 的 setup、rolling update,怎么去解决 Kubernetes 对于本地磁盘存储的绑定问题。
所以面临着一个与大家之前在 Kubernetes 上去部署带状态的服务非常接近的问题。因为 TiDB 本身是一个带状态的数据库,数据库没有状态那不可能。Kubernetes 的调度其实是对这种 stateless applications 非常友好的,但是如果你是一个带状态的,比如像 MySQL、PG、TiDB,或者 Etcd、Zookeeper 等等,怎么去做?真正的困难并不是 Kubernetes 做不了,而是每一个不同的系统都有自己的数据分布模型,同时每一个不同的系统它的运维方式也不太一样。所以作为 Kubernetes 的平台来说,没有办法去针对每一个不同的存储系统去设计一套自己的调度策略。这是 Kubernetes 没有办法去做的一个事情。
举个例子,比如说你想去运维好一个 Redis Cluster,那你必须得了解 Redis Cluster 一些原理,还有必须得去知道它怎么运维;如果你想要去运维 Codis,你必须得知道 Codis 的一些原理方法才能把它运维好。但这些领域知识怎么去告诉 Kubernetes 说你帮我按照这个方法来去运维这个系统?
这时候有一个公司,叫做 CoreOS,相信大家可能也都熟悉,就是 Etcd 背后的那个公司,也是我们 PingCAP 的好伙伴。CoreOS 也是社区里面最大的 Kubernetes 的运营的公司,他们引入了一个新的 Kubernetes 的组件,叫做 Operator。Operator 的意义在于它其实是相当于使用了 Kubernetes 的 TPR ( third party resources )的 API,去把你的系统运维的一些领域知识,封装到 Operator 里面,然后把 Operator 这个模块注入到 Kubernetes 上面,整个这些集群是通过 Operator 这个模块来去做调度。
CoreOS 官方还提供了一个 Etcd 的 Operator 的实现。其实这思路也很简单,就是说把这个集群的创建滚动更新,然后各种运维的一些领域知识放到这个 Operator 里面,然后在 Operator 里面去调用 Kubernetes 原生的 API,来做集群的管理,相当于是 Kubernetes 的一个 Hook。
一般来说一个 Operator 它其实有这样一些对外暴露的接口或者是能力。它做的事情的就是:比如我想要让 Kubernetes 去建立一个 TiDB 的集群,比如说 deployment ;比如我加入新的物理节点以后,我要想对现有的这个集群做扩容,然后 rebalance ;比如说我的集群的 TiDB 本身的这些 binary 需要升级,我要去做业务透明的滚动更新,比如说我有 100 个节点,要在上面去做升级,不可能手动去做,这个其实都是封装在我们的 Operator 里面,然后包括自动化的 backup 跟 restore 这些功能。
本质上来说你可以认为 Operator 是一个 Kubernetes 的批处理方案。我刚才也简单提到了一下,Kubernetes 可以作为一个集群的操作系统,但是这个操作系统总应该能让运维去写脚本的,这个脚本就是 Operator 机制。
其实它的原理很简单,就是它注入到 Kubernetes 里面,会实时不停的去观察集群的状态,去 Hook Kubernetes 的一些集群的状态,一些 API,然后得到整个集群的状态。把一些分析的东西放在 Operator 里面,它可能会有一些地方被触发,比如说我该扩容了或者我该去做 Failover,然后去反馈。
然后 TiDB 的 Operator 目前来说有这么几个功能:创建集群、滚动更新、Scale out,Failover、Backup/Restore。
因为其实今天的这个话题是说怎么去跟云做结合。我们现在在跟一些公有云的提供方在做合作。但是不可能说每一个公有云都自己去接入它的资源管理的 API,因为每个公有云可能都用的是不一样的 API database,所以我们相当于做的一个方案就是说,不管你是公有云也好还是私有云也好,你给我一堆物理的机器,然后在这一堆物理的机器上面去部署 Kubernetes,在这个 Kubernetes 上面,我相当于把我的 TiDB Operator 给放进去,当某个公有云客户要它去创建一个集群的时候,会通知 Operator 去创建,比如说划出一些机器,去做物理隔离。
这在私有云里边也是一个比较常见的场景了。用户他其实想要去做这种业务之间的租户隔离,TiDB Operator 是做一个比较简单的物理隔离。
但是做这个 Operator 最难的一个部分其实刚才也简单讲了一下,就是存储的问题。如果大家关注 Kubernetes 社区的话,一般都会注意到 persistend local storage 的这个方案一直在社区里边扯皮和吵架。现在大家认为 Kubernetes 本地的磁盘是没法用的,或者说没有办法直接当做一个资源来使用的。
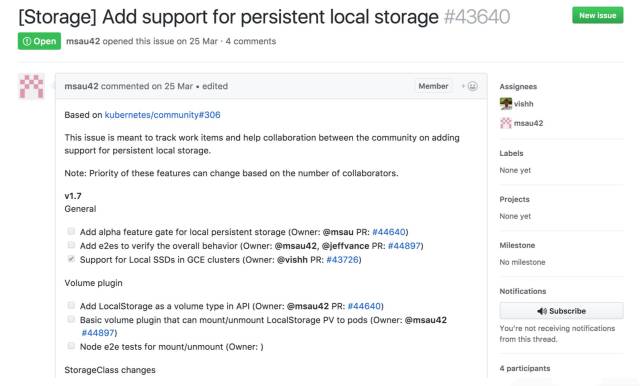
上图是放在 Kubernetes 的 issues 里面的一个问题,就是 persistent local storage,这个看上去非常不可思议,这么简单的功能为什么一直到现在没有支持。
我个人感觉 Google 之所以迟迟不去做这个功能,它背后有一个原因可能是在 Google 内部,它的网络存储是非常强的,它有自己非常好的网络设备。你在同一个数据中心里,去换一块网络盘,它的这个 latency 基本上很多业务可以接受的,所以这样的话,持久化存储的问题基本上是靠网络的磁盘来解决。
想像你跑一个 MySQL 的业务,MySQL 的业务本身它写入的磁盘并不是你的物理机的本地盘,而是一块网络盘,这个网络盘我能给你保证它的 IOPS 跟 latency 都是非常好的状态,这个时候你的业务挂掉了,我再重新启一个容器把这个网络盘再挂到那个 pod 的后边,这时候你的业务是几乎无感知的。这也是 Google 比较推崇的使用存储的一个模式,所以这就是 Kubernetes 背后的那个 persistent volumes 的这个方案。
它现在是有这个方案的,但是对于像我们这样的分布式数据库或者说对这种本地磁盘有特别强要求的( TiDB 底层的存储引擎对单机的 SSD 做了非常多的优化),并没有办法去容忍我底下写入的一个磁盘是网络盘。因为本身比如说 TiDB 这一层,已经做了三个副本,甚至五个副本的复制,但是在底下网络盘又要去做这个复制其实是没有太多必要的,所以 Google 一直迟迟没有推 Local Storage Resource。如果在 Google Cloud 上它能更好的去卖它的云盘,或者说对于这些公有云厂商来说,这是更友好的。
当然它也不是没做,它是要在 1.9 里面才会去做这个支持,但以 Kubernetes 社区的迭代速度,我估计 1.9 可能还要等个两三年,所以这是完全不能忍的一个状态。那既然我们又需要这个本地磁盘的支持,但是官方又没有,那该怎么办呢?这时我们就发挥主观能动性了。
我们给 Kubernetes 做了一个 patch。这个 patch 也是通过 Kubernetes resource 的方案去做的一个本地磁盘资源的管理模块,这个怎么做的呢?也比较简单。这部分内容就比较干了,需要大家对 Kubernetes 整个架构有一点点了解。
第一步,先会去创建一个 Kubernetes 的 Configuration map,我们称之为 TiDB 的 storage,就是针对 storage 的物理资源写在配置的文件里边。比如说机器的 IP,它的不同盘对应的文件夹在哪儿,相当于是一个配置阶段的东西。
第二步,创建一个利用 Kubernetes 的 Third Party Resources ( TPR ) 的 API,去创建一个叫 tidb-volume 的第三方资源,然后这个资源去刚才 Configuration map 里面去读它去注册的那些物理磁盘分布的状态资源,相当于 TPR 会把那个配置里面的磁盘资源 load 出来,变成在 Kubernetes 里的一个第三方 resource,这个对象大概是这样一个状态。
第三步,我们在这边会去写一个 controller,我们写这个 controller 是干嘛呢?叫 volume-controller。比如说我们的一个磁盘的资源分配给了一个 pod,然后这个 pod 现在在占用着这个资源,我需要有一个 controller 的模块来标记这个资源的使用情况,不能说我新的业务在起来的时候,我把资源分配给了两个正在用的业务,这是不行的。这里的对应关系其实是由 volume controller 去维护的。然后另外一方面它还实时的监盯着刚才 Configuration map 里面的物理资源,我可以动态的添加物理的磁盘资源的一些状态。
第四步,刚才我们说到 opreator 其实是一个运维的工具,去做创建集群还有滚动升级,相当于总的入口。在这里面在去创建集群,在启动进程的时候,把刚才我们创建的本地磁盘资源启动实例绑定在一起,让它能够成功的创建这个资源。
第五步,就是创建一个 DaemonSet。DaemonSet 在 Kubernetes 里就是在每一个物理节点上每一个长度的进程,这个进程是用来去维护磁盘上资源的使用状况。比如说一个 TiKV 的节点下线了,这个物理的磁盘资源就要被回收。回收了以后你要去做删除数据、清空数据的操作,或者这个物理机就宕机了,你需要有一个东西来去通知 controllor 把这个资源给下线掉,这个是 DaemonSet 在干的事情。
这一整套加起来就是相当于只通过 Third Party Resources 来嵌入 Kubernetes,整体来说在旁路却实现了一种本地的 local 磁盘的管理方案。
因为这个代码其实还蛮多的,现在还没有办法直接 push 回 Kubernetes 社区。虽然现在这还是一个 private 的项目,但是在后续把代码整理以后我们还是会开源出来。所以这其实也是为大家以后在 Kubernetes 去调度这种单双向服务的方案,提供了一套可行的路,至少我们用这个还挺爽的。
然后,想稍微展望一下未来的数据库应该是什么样的。
在我看来,未来的数据库不会再需要 DBA,或者说未来你在写业务的时候,并不需要去关心底下数据该去怎么分片,怎么去 sharding,一切都应该是在后面的云服务本身或者基础设施去提供的。所有的东西都应该是 self-driving,相当于自动驾驶。就像在未来大家觉得自动驾驶应该是一个方向,在基础软件里我觉得也是越来越多的自动化导致大家对运维的依赖变得越来越轻。但是在很多的极端的情况下,circuit-breaker (断路器)还是要有的。比如说我的业务产品现在突然出现了一个特别热的热点,我需要业务这边去紧急的做手动的数据切分、移动,把负载手动的均衡出来,所以手动模式还是仍然要有的。类似于你自动驾驶的汽车,突然来一个人加塞,大家还是非常希望能保证自己的安全,那就必须得有一个手动的模式。
第二点是 database as a service,前面也说到了,serverless 可能会在 database 里面,有一种新的形态的数据的数据库。大家如果关注数据库领域的话,最近出了一个新的数据库叫 FaunaDB。FaunaDB 非常有意思,它其实是跟公有云绑定在一起对外提供服务的,你看不见它实际的进程和部署,也看不见它物理的进程在什么地方,整个数据库对外的展现形式就是你去买我的服务,我给你多少的 QPS。比如说你买一万个 QPS,这个服务就能保证一万个 QPS,你买十万就是十万,按这个价格来去付费,至于你的容量全都是在背后隐藏着,所有业务的开发者实际上是看不见。
第三点就是 Local storage isn ’ t necessary。为什么 Google 它一直没有在 Kubernetes 里面去做 Local storage,其实仔细想一下也是有道理的,就是说随着未来硬件的发展,当网络社会的速度和分布跟你的磁盘的存储差不多的时候,那它到底是不是网络的,已经对业务层没有什么意义了,所以这可能是一个未来的趋势。
这条是一个比较极端的路,就是把整个磁盘放到网络上,用网络盘。还有另外一条反向的特别极端的路,也是我现在正在尝试的一个东西,就是更加去对硬件做定制。比如说我现在尝试把一些 TiDB 的数据库的一些逻辑放到 FPGA 上面,或者是放在 SSD 的控制芯片里面,这其实是更深的定制,在未来我觉得两者可能会融合。就是说我虽然可能是挂了一个网络盘,但是对于数据库来说我有了这个计算逻辑可能直接的去操作硬件,而不需要去例如通过标准的 POSIX API 来转换内核走 本地 IO 的接口。
总结一下,分布式系统的运维特别的痛苦,然后 Kubernetes 是一个未来集群调度必然的趋势,但是在存储层它现在还没有太多的好办法。目前来说我们在做的一个事情就是 Operator,把整个存储层的运维的领域知识放在 Operator 里边,然后让 Kubernetes 能去调度我们的东西。这个有点像 DCOS 的 batch script。
TiDB-Operator,其实是把运维干的事情,全都通过 Operator 的形式来封装在程序里边,然后自动的去运维。
Local Storage 的问题我们是解决了。虽然 Kubernetes 没有办法去提供这个能力,但是我们暂时解决了。
7 条回复 • 2017-06-03 21:16:36 +08:00
 |
1
vimsucks 2017-06-03 16:42:54 +08:00 看成黄旭东的肯定不止我一个
|
 |
2
LokiSharp 2017-06-03 16:45:20 +08:00 via iPhone
我知道下一句你们要说什么,干死黄旭东!
|
 |
3
cherrybob 2017-06-03 16:54:45 +08:00
飞龙骑脸怎么输
|
 |
4
Daniel65536 2017-06-03 17:03:20 +08:00 via iPad
三个巨像 A 不死人
|

 |
6
nieyujiang 2017-06-03 20:24:46 +08:00
干死黄旭东!啊,Sorry,看错了.手动滑稽.
|
 |
7
scnace 2017-06-03 21:16:36 +08:00 via Android
满满干货!但是我还是要说 干死黄旭东,不朽能对空!
|