推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

(推广)Github 项目,使用知乎移动端 APP 的 API 爬取数据
ksaa0096329 · 2017-11-15 10:20:31 +08:00 · 3321 次点击这是一个创建于 2709 天前的主题,其中的信息可能已经有所发展或是发生改变。
项目地址:gavin66/zhihu_crawler
目前项目已实现知乎的自动登录,并可爬取用户资料数据(还未有学历等详细资料,之后会添加),需要数据进行分析的或者感兴趣的可以给个 star⭐,谢谢。
使用方法
你必须安装有 mongoDB
安装依赖
pip install -r requirements.tx
爬取用户信息保存进 mongodb 中
python zhihu_crawler/spider/profile.py
配置
文件 config.py 进行项目运行配置
# mongodb 连接配置
MONGO_URI = 'mongodb://%s:%s@%s:%s/admin' % ('username', 'password', 'ip', 'port')
# 以下两个文件路径可随意换成你指定的
# token 默认保存地址
TOKEN_PATH = os.environ['HOME'] + '/zhihu_crawler/zhihu.token'
# 日志文件
LOG_PATH = os.environ['HOME'] + '/zhihu_crawler/zhihu.log'
API 说明
from zhihu.client import Client
# 所有程序的入口
client = Client()
# 直接使用用户名和密码登录
client.login(username='+8615555555555', password='password')
# 不使用参数,根据命令行输入
# client.login()
# 自己 model
myself = client.myself()
# 自己的信息
myself.info()
# 他人 model
people = client.people()
# 某人关注列表
people.followees()
# 某人被关注列表
people.followers()
运行截图
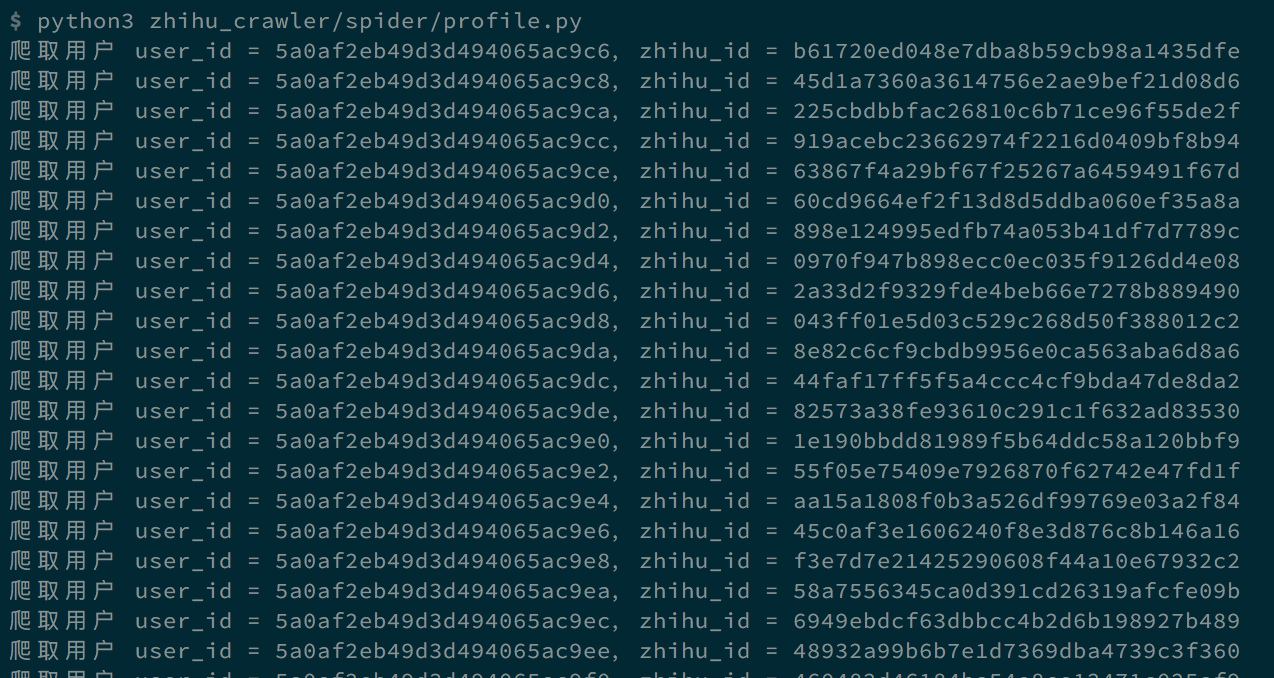
爬取数据的格式
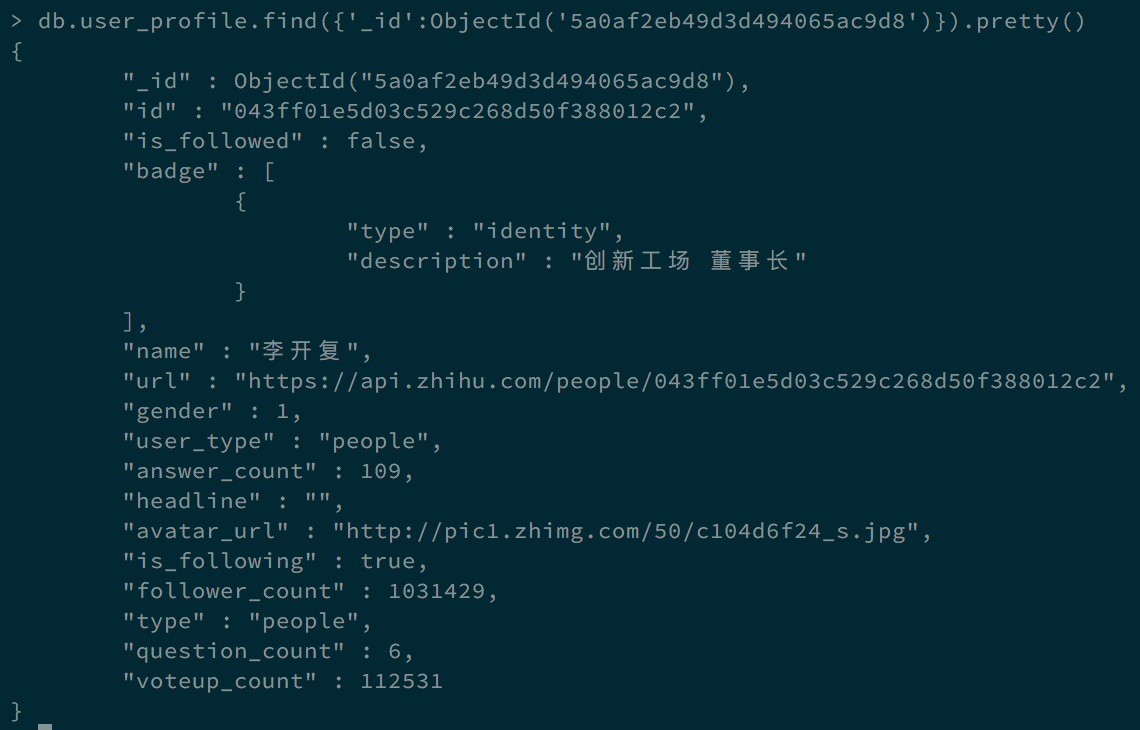
参考
- 登录部分的实现在本人博客有说明 - 爬取知乎数据 - 模拟登录
 |
1
bkmi 2017-11-15 12:33:04 +08:00 via Android
扒接口算侵权么
|
 |
2
stop9125 2017-11-15 13:22:43 +08:00 via iPhone
拔完还要亮出来
|
 |
3
qdzzyb 2017-11-15 13:41:11 +08:00
倒逼知乎成长
|
 |
4
mingyun 2017-11-19 22:45:10 +08:00
厉害了 apk 还能反编译了
|