推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

这是一个创建于 2580 天前的主题,其中的信息可能已经有所发展或是发生改变。
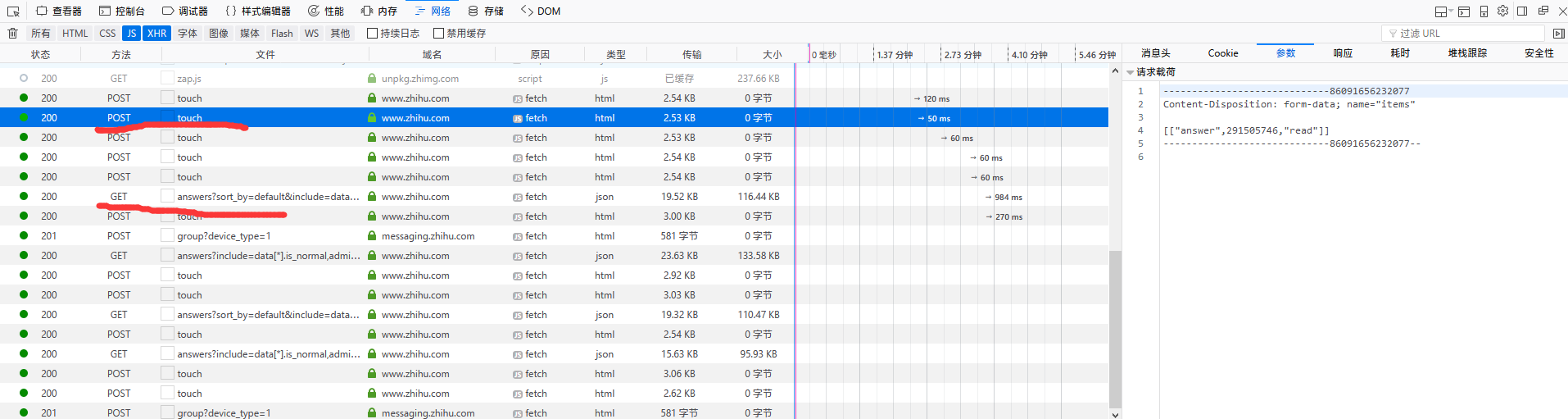
初学 python,想到用这个练手,但是知乎的答案是动态加载的,每次网页滚动一定距离就会发送一个 POST 请求,当滚动到末尾的时候就会发送 GET 请求,加载新的内容,求思路,谢谢
 |
1
frostming 2018-01-10 10:42:25 +08:00
就是那个 GET 请求,一定有 offset, page 等参数。JSON 的多好处理
|
 |
2
kiritoyui OP ```python
https://www.zhihu.com/api/v4/questions/265062021/answers?sort_by=default&include=data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,upvoted_followees;data[*].mark_infos[*].url;data[*].author.follower_count,badge[?(type=best_answerer)].topics&limit=20&offset=23 https://www.zhihu.com/api/v4/questions/265062021/answers?sort_by=default&include=data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,upvoted_followees;data[*].mark_infos[*].url;data[*].author.follower_count,badge[?(type=best_answerer)].topics&limit=20&offset=63 https://www.zhihu.com/api/v4/questions/265062021/answers?include=data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,upvoted_followees;data[*].mark_infos[*].url;data[*].author.follower_count,badge[?(type=best_answerer)].topics&limit=20&offset=83&sort_by=default ``` 加载更多和 GET 请求末尾的 offset 有关,但是请求 URL 似乎不是固定的 |
 |
3
qwjhb 2018-01-10 10:49:16 +08:00
不是固定 url 么 只是参数顺序变了而已吧 又没关系
|
 |
4
njwangchuan 2018-01-10 17:50:27 +08:00
最近刚好做了一个应用,不过我用的是 nodejs,爬取范围比楼主的稍微大点,一个话题下所有图片。
基于爬虫的应用,关键点其实不在于能爬到内容并解析,而是建立一个爬取体系,能够分步骤可靠并可控的爬取所需内容。具体到楼主这个需求,可以分几步: 1、找一款合适的知乎爬虫 sdk,研究下 api 参数,我用的是: https://github.com/shanelau/zhihu。 2、对于一个问题,第一次先爬取所有回答,后续用定时任务爬取更新的回答。 3、另起一个定时任务,解析每个回答中的文本信息,提取图片并保存。 4、另起一个定时任务,对图片进行后续处理。比如识别下是不是妹子什么的。 |
 |
5
winglight2016 2018-01-10 18:33:59 +08:00
@njwangchuan 学习了,我之前都是全部自己写,没想到已经有轮子了这个前提
|
 |
6
mundane 2018-01-11 18:41:48 +08:00
|
|
8
kiritoyui OP @frostming 我发现有的图片加载不出来 这个是什么问题?比如这个 https://pic3.zhimg.com/0bea957c8c4c92cfd1713a62e55bbb28_r.jpg 直接访问也是只能加载部分,我看了下我扒下来的所有图片,不好图片都是这样的
|
|
9
mundane 2018-01-14 10:37:17 +08:00
在 header 加上 refer 试试, https://zhuanlan.zhihu.com/p/30537226
|