
这是一个创建于 2587 天前的主题,其中的信息可能已经有所发展或是发生改变。
背景
2017 年年初以来,随着 Redis 产品的用户量越来越大,接入服务越来越多,再加上美团点评 Memcache 和 Redis 两套缓存融合,Redis 服务端的总体请求量从年初最开始日访问量百亿次级别上涨到高峰时段的万亿次级别,给运维和架构团队都带来了极大的挑战。
原本稳定的环境也因为请求量的上涨带来了很多不稳定的因素,其中一直困扰我们的就是网卡丢包问题。起初线上存在部分 Redis 节点还在使用千兆网卡的老旧服务器,而缓存服务往往需要承载极高的查询量,并要求毫秒级的响应速度,如此一来千兆网卡很快就出现了瓶颈。经过整治,我们将千兆网卡服务器替换为了万兆网卡服务器,本以为可以高枕无忧,但是没想到,在业务高峰时段,机器也竟然出现了丢包问题,而此时网卡带宽使用还远远没有达到瓶颈。
定位网络丢包的原因
从异常指标入手
首先,我们在系统监控的 net.if.in.dropped 指标中,看到有大量数据丢包异常,那么第一步就是要了解这个指标代表什么。
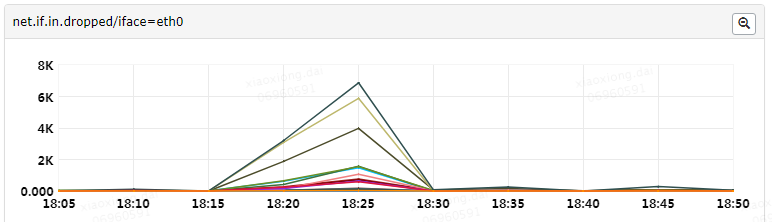
更多详情点这里: https://tech.meituan.com/Redis_High_Concurrency_Optimization.html

 |
1
watzds 2018-03-20 13:59:34 +08:00 via Android
美团的技术文章是不错
|
 |
2
meituandianping OP @watzds 多谢肯定:)
|
 |
3
JamesRuan 2018-03-20 21:17:55 +08:00
看到中断就猜到是利用 multiqueue 特性设置 cpu 的 affinity 了。
只不过人家是翻内核代码确认的,我是猜的…… |