
raft 中 log replication 的可能造成 leader 丢失已经 committed 的 log 问题
WithSalt · 2019-02-16 15:41:27 +08:00 · 2347 次点击这是一个创建于 2150 天前的主题,其中的信息可能已经有所发展或是发生改变。
- 如下图(C)的情况:
问题一:
- 当 leader S1 收到其他大多数 node 的 AppendEntryReply(AER)的成功时,也就是大多数成功 replicate以后,标记当前 log(s)为 commit 状态,更新 commitIndex,然后 apply 到状态机中。
- 我的实现是在下一次的 HeartBeat(HB)或者 AE 分发的时候,follower 才更新刚才的 log 的状态为 commit,如果在 leader 更新完 commitIndex 但没有完成向 follower 发送确认时,leader failed(收到更高的 term 的 RequestVote 或者 AE,然后 turn to follower)。
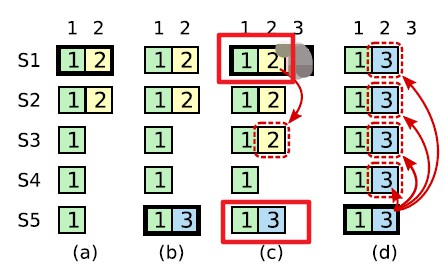
- 这和 figure8 的情况有点类似,这次的问题是:原来的 leader S1 已经把 Term2 的 log commit 掉了(更新了 commitIndex),后来的 leader S5 又修改了那个 index 对应的 log,因为 commit 以后不能在修改,这样原来的 leader S1 恢复以后,没有办法接受新 leader S5 的 log,也没有办法在成为 leader,就卡在这了,怎么破?
问题二:
- 如果在图中(c)中 Term2 的 log 在所有节点上都成功 commit,然后 leader 宕掉,S5 被选为 leader,这时 Term2 的 log 不也会被 overwrite 掉吗?
 |
1
Wisho 2019-02-16 16:58:16 +08:00 不是很懂你的问题二。
论文里这个原图的意思应该是: (a)时刻,S1 当选,term 号为 2,然后接到客户端的请求,在本地写入(term=2, index=2)的 entry,然后开始 replicate,replicate 到 S2 上,结果意外发生,S1 宕机。 (b)时刻,S1 宕机一段时间后,S5 的 timeout 结束,恰好能参选,发现自己的 latest entry 是(term=1, index=1),还是和大部分人( S3, S4, S5 自己)的 latest entry 保持一致,所以 S5 能够成功当选 leader,term 号为 3。然后马上接到客户端的请求,在本地写入了(term=3, index=2)的 entry,然而 S5 的命运更悲催,还没来得及给兄弟们 replicate,自己就宕机了。 (c)时刻,S5 宕机一段时间后,S1 的 timeout 正好最先结束,决定参选,发现自己的 latest entry 是(term=2, index=2),S2、S3 和 S1 自己都愿意投给 S1,S1 又顺利当选,term 号为 4。此时刚把之前还未完成 replication 的(term=2, index=2)的 entry 分发给 S3,又收到了客户端的请求,请求写入(term=4, index=3)的 entry 到本地。 所以你是指,在(c)时刻,作为 term=4 的 leader,S1 当选后 N 久都收不到客户端的请求写入(term=4, index=3)的 entry,所以有充足的时间把(term=2, index=2)的 entry 分发到所有兄弟上,且 commit 吗? 但是 raft 里的约定就是,term=X 的 leader 是不能直接 commit term < X 的任何记录的,只能在 commit term=X 的记录时把历史上分发成功但是没有 commit 的“顺手” commit 了。 |
|
2
Wisho 2019-02-16 17:14:37 +08:00 接上条回复。
正因为 raft 的这个约定,所以在(c)时刻,即使 S1 这个 term=4 的 leader 把(term=2, index=2)的 entry 成功分发到 S1、S2、S3、S4 上(超过半数),它也不能 commit。不能 commit 就意味着不能回复客户端:“您好,您的操作已生效”,那客户端的“期望”就不会是“哦,存储系统已经帮我存好了,我可以放心了”。 如果在成功分发到 S1、S2、S3、S4 上后(注意是分发成功,但未 commit,未能回复客户端),马上 S1 宕机了。又是那么巧,又是 S5 上线参选,S5 发现“咦? S2、S3、S4 上的 latest entry 都只是(term=2, index=2)而已,我自己最新的是(term=3, index=2),比它们的都新”,所以 S5 能得到大家的投票,S5 当选,term 号为 5。S5 当选后,第一件事就是统一兄弟们的 log entries,一把梭就把(term=3, index=2)分发给大家,直接 overwrite 掉兄弟上的历史记录。 但是这个 overwrite 没关系呀!很正常!为啥没关系,很正常?记得上面我强调的那个“分发成功,但未 commit,未能回复客户端”吗?只要没能 commit 成功,没能回复客户端成功,客户端会认为系统没有给我完成“存储”或者没有给我完成“某种数据操作”,所以客户端也许会超时重试、也许会放弃(取决于具体的业务逻辑)。 但如果你 commit 了(term=2, index=2)的 entry,告诉客户端“放心,成功持久化了”,结果之后被 S5 的(term=3, index=2)给 overwrite 了的话,这会是你的系统的严重失误!分明之前告诉客户端放心没问题存好了,但是之后又“出尔反尔”,把别人的数据给 overwrite 直接搞丢了,就是严重失误。 所以,一切的前提就是 raft 的这个约定,一个非常重要的约定:term=X 的 leader 不能直接 commit term < X 的任何记录,可以分发但不能 commit,直到要 commit term=X 的记录时才能“顺手” commit 历史记录。 |
|
3
Wisho 2019-02-16 17:14:52 +08:00 希望我讲清楚了吧😂
|
