推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

这是一个创建于 1957 天前的主题,其中的信息可能已经有所发展或是发生改变。
假设表
data = [
['20:00', 100],
['20:10', 130],
['20:20', 190],
...
]
期望结果,只统计增量:
data = [
['20:00', 100],
['20:10', 30],
['20:20', 60],
...
]
正常写法我会,求一个最 pythonic 的搞法。
印象中好像 map 还是 reduce 啥的能搞这个,但是 py3 好像要导入模块,有点想不起来了。
谁给指点一下。
 |
1
necomancer 2019-12-11 21:54:10 +08:00
In [1]: [data[0], list(map(lambda x, y: [x[0],y[1]-x[1]], *zip(data[:-1],data[1:])))]
Out[1]: [['20:00', 100], [['20:00', 30], ['20:10', 60]]] |
 |
2
watsy0007 2019-12-11 22:00:19 +08:00
```python
fst = lambda x: x[0] sec = lambda x: x[1] [[fst(item), sec(item) - (0 if idx == 0 else sec(data[idx-1]))] for idx, item in enumerate(data)] ``` |
|
3
necomancer 2019-12-11 22:00:58 +08:00
sorry
[data[0]] + list(map(lambda x, y: [x[0],y[1]-x[1]], *zip(data[:-1],data[1:]))) |
|
4
necomancer 2019-12-11 22:08:13 +08:00
再 sorry,没看清题……
In [3]: [data[0]] + list(map(lambda x, y: [y[0],y[1]-x[1]], *zip(data[:-1],data[1:]))) Out[3]: [['20:00', 100], ['20:10', 30], ['20:20', 60]] |
 |
5
JCZ2MkKb5S8ZX9pq OP @necomancer 好像是 zip 这步有点问题,py3.7。
TypeError: <lambda>() takes 2 positional arguments but 55 were given 还是 map 的调用方法问题? 我要试试,这两个方法不大用到。 |
|
6
JCZ2MkKb5S8ZX9pq OP 顺便给一串测试数据好了,里面是排序后的 tuple。
[('2019-12-09 19:40:03', 412), ('2019-12-09 20:10:58', 4136), ('2019-12-09 20:41:00', 6634), ('2019-12-09 21:11:22', 9090), ('2019-12-09 21:41:23', 11636), ('2019-12-09 22:11:27', 14597), ('2019-12-09 22:41:32', 17506), ('2019-12-09 23:11:43', 20315), ('2019-12-09 23:41:44', 22926), ('2019-12-10 00:11:46', 24749), ('2019-12-10 00:41:55', 26133), ('2019-12-10 01:11:58', 27021), ('2019-12-10 01:42:06', 27574), ('2019-12-10 03:08:38', 28333), ('2019-12-10 03:38:48', 28435), ('2019-12-10 04:08:58', 28527), ('2019-12-10 04:39:01', 28608), ('2019-12-10 05:09:23', 28680), ('2019-12-10 05:39:32', 28754), ('2019-12-10 06:09:46', 28841), ('2019-12-10 06:39:51', 29006), ('2019-12-10 07:09:57', 29320), ('2019-12-10 07:40:05', 29755), ('2019-12-10 08:10:51', 30309), ('2019-12-10 08:40:59', 30902), ('2019-12-10 09:11:08', 31454), ('2019-12-10 09:41:21', 31977), ('2019-12-10 10:11:48', 32555), ('2019-12-10 10:42:04', 33137), ('2019-12-10 11:12:30', 33749), ('2019-12-10 11:42:45', 34279), ('2019-12-10 12:12:55', 34964), ('2019-12-10 12:43:05', 35904), ('2019-12-10 13:13:27', 36774), ('2019-12-10 13:43:49', 37375), ('2019-12-10 14:13:56', 37803), ('2019-12-10 14:44:08', 38222), ('2019-12-10 15:14:40', 38589), ('2019-12-10 15:44:51', 38937), ('2019-12-10 16:15:04', 39311), ('2019-12-10 16:45:37', 39707), ('2019-12-10 17:15:53', 40081), ('2019-12-10 17:45:55', 40520), ('2019-12-10 18:16:05', 40991), ('2019-12-10 18:46:48', 41481), ('2019-12-10 19:17:01', 41999), ('2019-12-11 03:23:55', 47926), ('2019-12-11 05:24:01', 48053), ('2019-12-11 07:24:05', 48245), ('2019-12-11 09:24:18', 48742), ('2019-12-11 11:24:28', 49315), ('2019-12-11 13:24:41', 50181), ('2019-12-11 15:24:51', 50767), ('2019-12-11 17:24:52', 51305), ('2019-12-11 19:24:54', 52048), ('2019-12-11 21:25:34', 52911)] |
|
7
JCZ2MkKb5S8ZX9pq OP @necomancer 搜了下,看到 pandas 有个 diff 方法。
[pandas.DataFrame.diff — pandas 0.25.3 documentation]( https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.diff.html) |
|
8
necomancer 2019-12-11 22:19:40 +08:00
是……我脑残了……
[data[0]] + list(map(lambda x: [x[1][0],x[1][1]-x[0][1]], zip(data[:-1],data[1:]))) |
 |
9
ClericPy 2019-12-11 22:21:21 +08:00
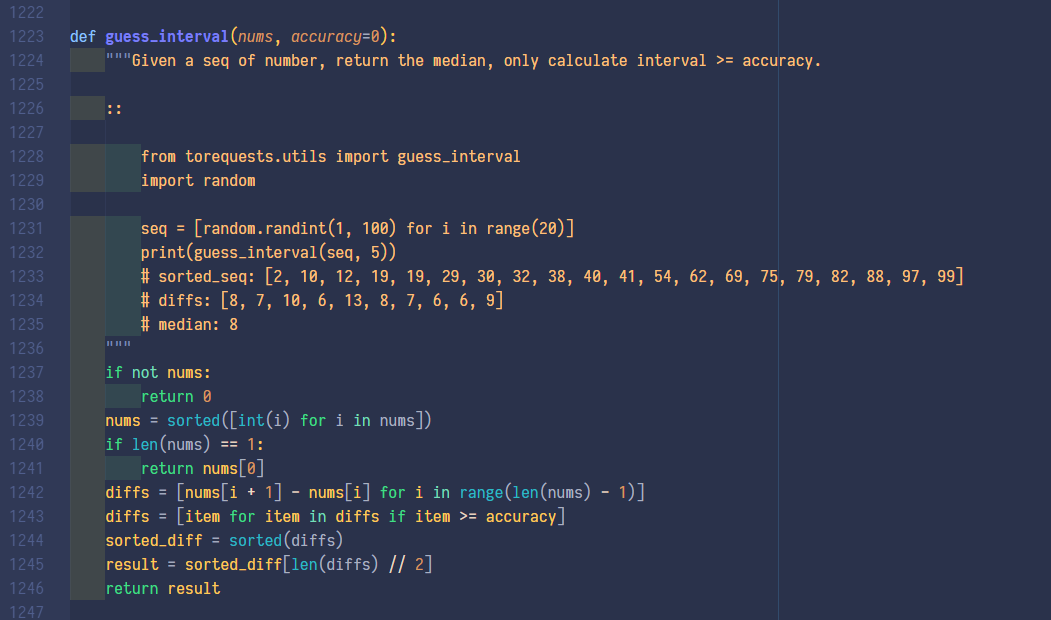
以前写过类似的有序一维数组判断间隔的, 取前几行改改也能用, 主要就是一行 diffs = [nums[i + 1] - nums[i] for i in range(len(nums) - 1)] pythonic 这种东西不是炫技, 牺牲可读性写出来的代码基本等同于蠢 |
|
10
necomancer 2019-12-11 22:24:52 +08:00
@ClericPy nums[i]这样会引入一个 O(N) 操作的。
|
 |
11
ipwx 2019-12-11 22:26:16 +08:00
你这个例子写个 for 难道不是可读性最好的么?
在这里追求所谓的“Pythonic”未免走火入魔了。 |
|
12
necomancer 2019-12-11 22:26:35 +08:00
@JCZ2MkKb5S8ZX9pq pandas 我用得不多。pandas 倒是支持时间作差,但必须是 pandas 的 datetime 类型,字符串直接带入会报错。
|
|
13
JCZ2MkKb5S8ZX9pq OP @necomancer
df = pd.DataFrame(data, columns=['time', 'volume']) df['volume'] = df['volume'].diff() df['volume'].fillna(0, inplace=True) df['volume'] = df['volume'].astype(int) print(df) diff 可以应用在单独的 series,就是它不打 0 而是用 nan,还要再转一下。 |
|
14
necomancer 2019-12-11 22:45:37 +08:00 @JCZ2MkKb5S8ZX9pq 这样啊,谢谢。不过我看求 diff 的时候 pd 好像没有 numpy.diff 里的 prepend 功能,所以无论如何少一个。按你的要求是第一个值不变,原始数据应该在头一个加一个['---', 0] 进去吧~
|
|
15
necomancer 2019-12-11 22:46:27 +08:00
或者直接 df['volume'] = numpy.diff(df['volume'], prepend=0)
|
|
16
JCZ2MkKb5S8ZX9pq OP @necomancer
其实感觉这么搞,适用性的确不高。 如果数据内部想标清楚点,用 dict 来记录每一条,写起来更长,的确嵌套起来不大好读。 pandas 在这种地方还是挺好的。 以前都是简单表格直接 prettyTable,感觉 pandas 还是值得深入搞搞。 |
|
17
JCZ2MkKb5S8ZX9pq OP @necomancer 没错,pandas 第一个搞了 0 出来。你不说我还没注意。
|
|
18
JCZ2MkKb5S8ZX9pq OP |
|
19
JCZ2MkKb5S8ZX9pq OP @ClericPy 你这个是算间隔的话,长度 1 的时候为什么不是返回 0 ?
|
|
20
necomancer 2019-12-11 23:00:15 +08:00
@JCZ2MkKb5S8ZX9pq numpy 是基础。我是做物理的所以很少处理非数字的数据,pandas 除了 read_csv 啥的没咋用过。
但 pandas 的 dataframe 的底层似乎就是 numpy.ndarray,比如 df.values 会返回 numpy.ndarray ; numpy 的函数也更数学化。但 pandas 的 dataframe 针对各种复杂的数据似更友好一些。 |
|
21
necomancer 2019-12-11 23:03:30 +08:00
numpy 去官方文档看看那个入门了解一下各种数组的操作就可以了。你要是处理数据尤其是简单统计一类的比较多的话,多看看 pandas。有些像 dataframe.diff 不那么好用的场景毕竟还可以用 numpy.diff (prepend,append 和 axis ),毕竟数据应该是一样的。
|
 |
22
dongxiao 2019-12-11 23:19:52 +08:00 1、
data[0:1] + list(map(lambda obj1, obj2: [obj1[0], obj2[1]-obj1[1]], data[0:-1], data[1:])) 2、 from pandas import DataFrame frame = DataFrame(data) pd.concat([frame.loc[:, 0], frame.loc[:, 1].map(int).diff()], axis=1).combine_first(frame) |
|
23
JCZ2MkKb5S8ZX9pq OP @necomancer 好的,我去了解一下。
|
|
24
JCZ2MkKb5S8ZX9pq OP @dongxiao 这个是会玩 pandas 的,让我好好消化一下。
|
|
25
dongxiao 2019-12-11 23:42:25 +08:00 3、
import numpy as np arr = np.array(data) time_arr, num_arr = np.hsplit(arr, [1]) np.c_[time_arr, np.r_[num_arr[:1], np.diff(num_arr.astype(int), 1, 0)]] # 如果要格式转换则 list(map(lambda obj: [obj[0], int(obj[1])], np.c_[time_arr, np.r_[num_arr[:1], np.diff(num_arr.astype(int), 1, 0)]].tolist())) |
|
26
ClericPy 2019-12-12 01:46:31 +08:00
@JCZ2MkKb5S8ZX9pq #23 呃, 看了这么多回帖才知道你是要数据分析量级比较大的, 那走 pandas 肯定是最好的选择, 性能高一大截还不容易出错
@necomancer #10 好吧, 我还真没想到复杂度层面, 以前被 CTO 逮住教训了半天别太纠结语法糖, 写过太多屎山, 所以把 pythonic 就直接看作优雅的可读性了 |
 |
27
dangyuluo 2019-12-12 07:15:15 +08:00
最 pythonic 的写法难道不是用 numpy 么哈哈,shift 第二列然后减一下
|
 |
28
cassidyhere 2019-12-12 10:11:17 +08:00
from itertools import chain
l = [100, 130, 190] [i - j for i, j in zip(l, chain([0], l[:-1]))] 这样吧,如果想用 map 还可以用 operator import operator map(operator.sub, l, chain([0], l[:-1])) |
|
29
cassidyhere 2019-12-12 10:14:35 +08:00
涉及循环或序列里元素间的操作,可以看看 itertools, operator, functools
|
 |
30
wliansheng 2019-12-12 11:22:06 +08:00
为什么楼上大部分回答都不能成功运行。除了 @cassidyhere 可以得到 [100, 30, 60]
|
|
31
JCZ2MkKb5S8ZX9pq OP |
 |
32
cfwyy 2019-12-12 14:59:37 +08:00
不知道啥叫 pythonic,见笑了。
newdata=data[0:1] newdata.extend([[data[i][0],data[i][1]-data[i-1][1]] for i in range(1,len(data))]) |