
这是一个创建于 1850 天前的主题,其中的信息可能已经有所发展或是发生改变。
本文主要分析循环神经网络(RNN)的大致原理及其 TensorFlow 实现,文章后半部分详细介绍循环网络结合移动端的一次趣味实践:AI 诗人(别忘记点个 Star 哦)。
阅读更多文章 -> 博客链接
之前介绍的神经网络包括卷积网络,HED 网络等网络结构都是从输入层到隐藏层再到输出层,每次输入对应输出,输入、输出之间是无关联的。这些网络都无法提取时间序列的相关特征和上小文语义的相关特征,循环神经网络便是为了解决这类问题而生的。
循环神经网络输入的是一个序列,输出的也是序列,当然也可以视场景而定输出一个值。训练的时候可以学习到关于序列的特征,主要运用于语音识别、语言模型、机器翻译以及时序分析等方面。不仅仅局限于这些常见的应用场景,更多时候可以结合自己的实际需求寻找合适的网络,之前看到过有电商平台使用循环网络做用户的意图预测,用户在客户端上每次点击的内容作为一个序列,经过训练能预测出该用户后续是否有购买意图,对此有兴趣的可以点击该内容的原文。下面开始介绍循环神经网络,对此不敢兴趣的可以直接调至实践部分。
理解循环网络
对于循环神经网络,一个非常重要的概念就是时刻,会针对每一时刻的输入结合当前时刻的状态形成一个输出,并且更新当前状态,如下左图所视,循环神经网络的主体 A 的输入除了来自输入层 X t ,还有一个循环的边来提供当前时刻的状态,并输出一个值 h t 。同时 A 的状态会从当前步传递到下一步。理论上,循环神经网络可以看做同一个神经网络结构的无限复制,出于优化考虑,现实中会将循环体展开得到下图右边的部分。

循环神经网络示意图
对于最简单的循环网络,主体部分 A 可以是一个允许两个输入,两个输出全连接网络,示意图如下:
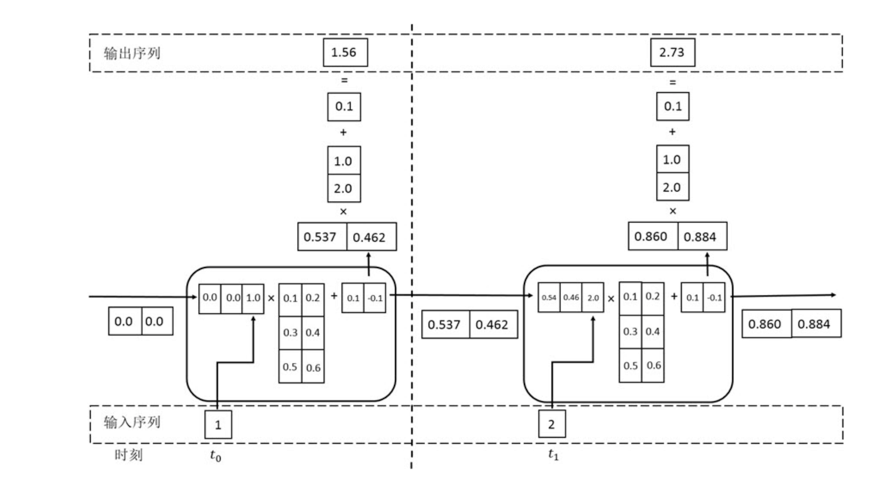
当然实际上并不会直接使用如此简单的全连接层作为循环的主体,这个例子是为了读者更好的理解循环网络,以及循环网络是同一个神经网络结构的无限复制这个概念。
标准的循环网络有个显而易见的问题:长期依赖( long-term dependencies )。实际问题中,有些时刻只需要依赖短期内的上下文信息,而有些时刻需要远期的上下文信息, 长短时记忆网络( long short term memory, LSTM )的设计就是为了解决这个问题。怎么解决呢? LSTM 是一种拥有三个“门”结构的特殊网络结构,它的内部有 4 个网络层(标准的循环网络只有一个网络层):

其中的门结构可以有选择性的影响网络中每一时刻的状态,由结构图也可以看出,所谓的门结构就是使用 sigmoid 层和一个点乘的操作,sigmoid 作为激活函数的全连接层会输出一个 0 到 1 之间的数值,用来控制信息通过的量,为 1 表示信息全部通过,为 0 时信息均不能通过。
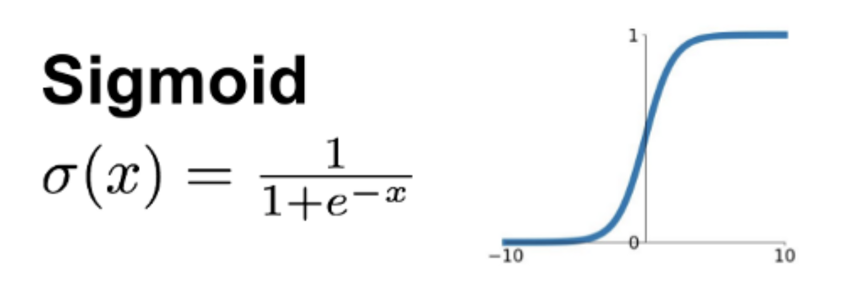
sigmoid 函数
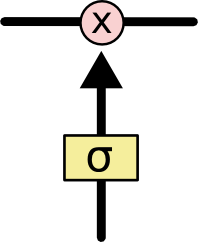
门结构
上文所说的三个门指的是忘记门,输入门和输出门。另外还有一个关键点是细胞状态( cell state ),贯穿始终,并且连接三个门结构。其中忘记门如下图所示:

忘记门决定了细胞状态需要丢弃哪些信息,通过输入 h__t-1 和 X__t 经过 sigmoid 层,输出 0 到 1 的值,表示需要保留或者丢弃多少上个细胞状态的信息 C__t-1 ,下面是输入门:

输入门决定给细胞状态添加多少信息,分为两个步骤,首先通过 h__t-1 和 X__t 经过 sigmoid 层得到的值决定更新哪些信息,然后通过 h__t-1 和 X__t 经过 tanh 层得到候选的细胞状态,最后上个步骤的值作用于候选细胞状态得到输入门的输出值。然后这个值会添加进原细胞状态中,更新为新的细胞状态 C__t ,如下所示:

最后是输出门,如下所示:

首先也是通过 h__t-1 和 X__t 经过 sigmoid 层得到 0 到 1 的值决定哪些信息需要输出,该值作用于新的细胞状态 C__t 经过 tanh 层最终得到输出值。以上就是长短时记忆网络的主要结构。由于 TensorFlow 为我们封装了内部结构,所以实现起一个循环网络的单元非常简单:
tf.nn.rnn_cell.LSTMCell(num_unit)
当然这只是一个循环单元,具体的使用在后续的应用文章中在介绍。其中参数 num_unit 表示网络的宽度,也是输出向量的宽度。比如在接下来介绍的自动写诗网络,输入向量大小为 [num_seqs, batch_size],LSTM 网络的输出为 [num_seqs, batch_size, num_unit],接下来介绍 LSTM 网络的移动端应用。
循环网络的移动端实践
AI 诗人:https://github.com/pqpo/AIPoet(别忘记点个 Star 哦!) 是我开源的一个趣味应用,无须联网随时随地写藏头诗、意境诗。使用 TensorFlow 实现的长短时记忆循环神经网络,针对五万多首唐诗进行训练,总共训练了 10w+,其中准确率达到了 70%+,并且将训练模型移植到 Android 客户端中,当然你也可以将训练出的模型移植到任意平台。应用截图如下:

1、数据预处理
开始之前先介绍一下该模型大致的实现过程,首先准备诗歌训练集,比如: “仙人浩歌望我来,应攀玉树长相待。”,接下来是将诗歌处理成训练数据,训练数据一般需要有输入和用于计算损失的输出,
输入:[仙人浩歌望我来,应攀玉树长相待]
输出:[人浩歌望我来,应攀玉树长相待。]
看出区别了吗?这样就是一对训练数据集,并且达到了预测下一个字的目的。
由于诗歌长短不一,为了提高运算效率,可以固定数组长度,过长的截取,不够的头部填充 0。为了让模型知道诗歌的开始和结束,定义了开始和结束符:<START>、<EOP>,这时候的训练集是这样的:
输入:[000000<START>仙人浩歌望我来,应攀玉树长相待]
输出:[000000 人浩歌望我来,应攀玉树长相待。<EOP>]
另外由于汉字不利于后续的数据处理与分析,故将汉字转化成数字,只需要统计一下有多少汉字,然后各自分配一个数字保证各自不重复即可,比如:
{
"word2ix": {
"憁": 4330,
"耀": 5499,
"枅": 6543,
"涉": 1324,
"谈": 2482,
...
}
}
为了方便后续训练,不再每次都预处理数据,将数据以二进制格式保存,下次直接使用二进制文件即可:
# 保存成二进制文件
np.savez_compressed(opt.pickle_path,
data=pad_data,
word2ix=word2ix,
ix2word=ix2word)
以上部分的详细代码查看:https://github.com/pqpo/AIPoet/blob/master/poetry-gen/data_utils.py
感谢 chinese-poetry 提供的诗歌数据
2、网络实现
下面是 TensorFlow 实现的网络部分,代码不多就全部贴出来了:
# [num_seqs, batch_size]
def char_rnn_net(inputs, num_classes, batch_size=128, is_training=True, num_layers=2, lstm_size=256, embedding_size=128):
if not is_training:
batch_size = 1
with tf.name_scope('embedding'):
embedding = tf.Variable(tf.truncated_normal(shape=[num_classes, embedding_size], stddev=0.1), name='embedding')
lstm_inputs = tf.nn.embedding_lookup(embedding, inputs)
with tf.namescope('lstm'):
cell = tf.nn.rnn_cell.MultiRNNCell(
[tf.nn.rnn_cell.LSTMCell(lstm_size, state_is_tuple=is_training) for _ in range(num_layers)],
state_is_tuple=is_training)
initial_state = cell.zero_state(batch_size, dtype=tf.float32)
x_sequence = tf.unstack(lstm_inputs)
lstm_outputs, hidden = tf.nn.static_rnn(cell, x_sequence, initial_state=initial_state)
x = tf.reshape(lstm_outputs, [-1, lstm_size])
output = tf.layers.dense(inputs=x, units=num_classes, activation=None)
endpoints = {'output': output, 'hidden': hidden, 'initial_state': initial_state}
return endpoints
首先需要注意的是输入向量的大小为 [num_seqs, batch_size],这是因为网络中使用的是 tf.nn.static_rnn 而非 tf.nn.dynamic_rnn,所以在此之前生成批量训练数据的时候做过一次转置:
def generate_batch_data(input, batch_size):
input_ = tf.convert_to_tensor(input)
data_set = tf.data.Dataset.from_tensor_slices(input_).shuffle(10000).repeat().batch(batch_size)
iterator = data_set.make_one_shot_iterator()
batch_data = iterator.get_next()
tensor = tf.transpose(batch_data)
input_batch, target_batch = tensor[:-1, :], tensor[1:, :]
return input_batch, target_batch
由于我们处理的中文数据,所以使用了 embedding 层,而不是简单的进行 one-hot, 如果处理的是英文可以考虑直接使用 one-hot 编码,每个单词都是一个维度,并且彼此独立。但是由于中文字符较多,常见的也有 3000 多个,one-hot 之后会变得很稀疏,不利于神经网络的学习。embedding 层可以使用一个较低维的向量表示出所有汉字,并且通过训练还能一定的表现出不同类别变量之间的关系。
一般为了使网络更加健壮适应更复杂的情况,可以叠加多个循环网络单元:
cell = tf.nn.rnn_cell.MultiRNNCell(
[tf.nn.rnn_cell.LSTMCell(lstm_size, state_is_tuple=is_training) for _ in range(num_layers)],
state_is_tuple=is_training)
这里叠加了 2 层,最终展开之后会如下图所示:
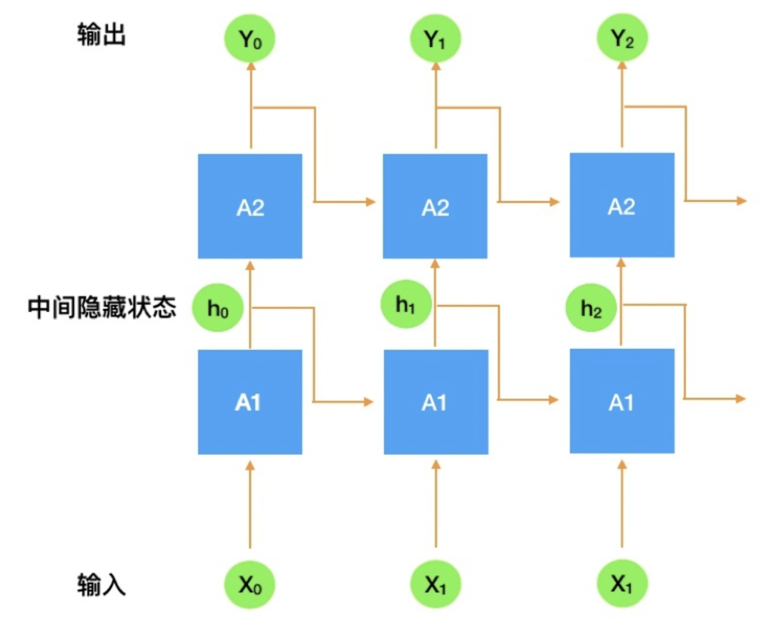
tf.nn.static_rnn 相比较于 tf.nn.dynamic_rnn,前者相当于是后者展开的形式,调用 dynamic_rnn 不会将 rnn 展开,而是利用 tf.while_loop 这个 api 生成一个开源执行循环的图,所以 static_rnn 生成图的时间会略慢于 dynamic_rnn,运行速度上两者是否有差距还有待实验验证。这里为什么使用 static_rnn 呢?原因是 static_rnn 可以更方便的转换为 TensorFlow Lite 模型,具体查看官方文档:转换 RNN 模型
使用 tf.nn.static_rnn 还有一个注意的地方是第二个参数是一个 tensor 数组,需要使用 tf.unstack 展开成 tensor 数组,x_sequence 是一个长度为 num_seqs 的数组,数组内容是 Shape 为 [batch_size, embedding_size] 的 Tensor 对象。
x_sequence = tf.unstack(lstm_inputs)
lstm_outputs, hidden = tf.nn.static_rnn(cell, x_sequence, initial_state=initial_state)
以上 static_rnn 的输出分两个部分 lstm_outputs 和 hidden,lstm_outputs 为正式的输出,并且是所有输出的集合,长度为 num_seqs 的数组,数组内的 Tensor 对象大小为[embedding_size, lstm_size] , 也就是原理篇介绍的输出门的输出 h__t , 另外还输出了一个 hidden,因为上述 LSTM 单元叠加了两层,所以 static_rnn 输出的第二个参数是个 tuple,分别表示两个 LSTM 单元的隐藏层,我们只看其中一个隐藏单元,从网络结构图上可以看出隐藏层输出由两部分组成 h__t 和 C__t ,它是一个 LSTMStateTuple 对象,里面包含了两个 Tensor 对象,大小均为 [embedding_size, lstm_size],并且隐藏层中的 h__t 是和输出层完全一致的。
最后经过一个全连接层转换为我们想要的 Shape 就可以输出了:
x = tf.reshape(lstm_outputs, [-1, lstm_size])
output = tf.layers.dense(inputs=x, units=num_classes, activation=None)
3、模型训练
训练环境
- 本地环境
Python 版本:3.7.2
TensorFlow 版本:1.13.2 - 训练环境
Google 免费提供的平台:Colaboratory
训练时推荐使用 GPU 环境,在自己的 macbook 上训练一轮需要 6 秒,如果没有 GPU 环境,可以免费使用 Colaboratory 的 GPU 平台,训练一轮缩短到 0.2 秒,提升了近 30 倍。
可以将训练脚本和预处理的二进制文件上传至 Google Driver,然后新建 ipynb 文件,在设置中选择 GPU 硬件加速,Python3 运行时类型。通过下面代码加载 Google Driver 目录:
from google.colab import drive
drive.mount('/content/gdrive')
import glob
glob.glob('gdrive/My Drive/poetry-gen/*')
运行之后会输出挂载的目录文件:
['gdrive/My Drive/poetry-gen/tang.npz',
'gdrive/My Drive/poetry-gen/char_rnn_net.py',
'gdrive/My Drive/poetry-gen/data_utils.py',
'gdrive/My Drive/poetry-gen/freeze_model.py',
'gdrive/My Drive/poetry-gen/sample.py',
'gdrive/My Drive/poetry-gen/utils.py',
'gdrive/My Drive/poetry-gen/config.py',
'gdrive/My Drive/poetry-gen/train.py']
由于文件路径会和本地的不一样,所以需要修改 config.py 中的相关文件路径,然后就可以执行脚本训练了,命令如下:
!python "/content/gdrive/My Drive/poetry-gen/train.py"
训练了 13w+ 次以后准确率达到了 70%+:
step: 134997/134997 loss: 1.5622 accuracy: 0.71 0.1806 sec/batch
4、模型验证与导出
之后就可以使用 sample.py 脚本验证模型效果了:
data, word2ix, ix2word = get_data(Config)
result = generate(u'床前明月光', word2ix, ix2word, prefix_words=u'郡邑浮前浦,波澜动远空。')
print(''.join(result))
## 床前明月光,门下旧欢情。橘柚吴姬醉,兰塘楚水行。烟霞随水鸟,苹藻逐仙英。藕花泳水声,桂酒留春并。...
# 藏头诗
result = gen_acrostic(u'床前明月光', word2ix, ix2word, prefix_words=u'郡邑浮前浦,波澜动远空。')
print(''.join(result))
# 床铺金钺肃,心耿白云生。
# 前席临清兴,五原分睿情。
# 明时廓无事,薄俸颇如名。
# 月出南山色,云昏北户阴。
# 光阴方熠素,幽沚忽参惊。
如果效果依旧不满意可以考虑继续训练一段时间。然后就可以导出为 TensorFlow Lite 的模型了:
converter = tf.contrib.lite.TFLiteConverter.from_session(sess, [inputs, initial_state],[output_tensor, hidden])
# converter.post_training_quantize = True
tflite_model = converter.convert()
open(FLAGS.output_file, 'wb').write(tflite_model)
这里并未开启量化开关( post_training_quantize ),量化之前模型大小为 17.5M ,量化之后模型大小为 7.8M ,虽然量化之后模型大小缩小了一倍,但是写诗效果也有所下降,所以使用了未量化的模型。需要注意的是导出之后模型的输入输出向量的类型和大小:
# 1.1 input shape is: (1, 1), name is: inputs:0, type is: <dtype: 'int32'>
# 1.2 input shape is: (1, 1024), name is: lstm/MultiRNNCellZeroState/MultiRNNCellZeroState/zeros:0, type is: <dtype: 'float32'>
# 2.1 output shape is: (1,), name is: outputs:0, type is: <dtype: 'int32'>
# 2.2 output shape is: (1, 1024), name is: lstm/rnn/rnn/multi_rnn_cell/concat:0, type is: <dtype: 'float32'>
输入和输出均有两个,其中包括输入的字符和输出的字符,以及大小为 (1, 1024) 的输入输出隐藏层,并且数值大小均为 32 位,为什么此次的隐藏层是一个 Tensor 对象呢?之前说的是 tuple 啊,原因是 Tensor 对象更方便数据的输入,所以将隐藏层转换成了 Tensor,只需要在构建网络的时候设置一个值就行( state_is_tuple=True ):
cell = tf.nn.rnn_cell.MultiRNNCell([tf.nn.rnn_cell.LSTMCell(lstm_size, state_is_tuple=True) for _ in range(num_layers)],state_is_tuple=True)
具体代码位于:https://github.com/pqpo/AIPoet/blob/master/poetry-gen/freeze_model.py
最后还要导出文字与数字的转换文件以供移动端使用:https://github.com/pqpo/AIPoet/blob/master/poetry-gen/export_convert.py
5、移动端集成
到这一步我们得到了两个文件,一个是模型文件,一个是 JSON 格式的数字文字转换文件,保存到 assets 目录中供 Android 程序读取。核心代码位于:https://github.com/pqpo/AIPoet/blob/master/app/src/main/java/me/pqpo/aipoet/core/AiPoet.kt
需要特别注意的是输入和输出参数:
input = ByteBuffer.allocateDirect(Int.SIZE_BYTES)
input.order(ByteOrder.nativeOrder())
output = ByteBuffer.allocateDirect(Int.SIZE_BYTES)
output.order(ByteOrder.nativeOrder())
states = arrayOf(
ByteBuffer.allocateDirect(HIDDEN_SIZE * Int.SIZE_BYTES),
ByteBuffer.allocateDirect(HIDDEN_SIZE * Int.SIZE_BYTES)
).apply {
this[0].order(ByteOrder.nativeOrder())
this[1].order(ByteOrder.nativeOrder())
}
其中 Int.SIZE_BYTES 大小为 4,正好是之前提到的 32 位数值大小( int32, float32 )。input 表示输入字符转换为数字的值,output 为输出的数字,经过转换得到字符。states 为一个长度为 2 的数组,里面保存的是输入和输出的隐藏层,HIDDEN_SIZE 大小为 1024,对应上述的 #1.2 与 #2.2。为何要设计成一个数组而非写死定义 input_state 和 output_state 呢?原因是这个时刻的输出状态是下个时刻的输入状态,写死定义之后需要进行一次数据的拷贝,具体逻辑参考如下代码:
@Synchronized
@Throws(UnmappedWordException::class)
fun fetchNext(word: String): String {
val wordIndex = convert.word2Index(word)
if (wordIndex == -1) {
throw UnmappedWordException(word)
}
val inputState = states[inputStateIndex]
val outputState = states[1 - inputStateIndex]
input.clear()
input.putInt(convert.word2Index(word))
inputState.rewind()
output.clear()
outputState.clear()
inputs[0] = input
inputs[1] = inputState
outputs[0] = output
outputs[1] = outputState
tfLite.runForMultipleInputsOutputs(inputs, outputs)
output.rewind()
inputStateIndex = 1 - inputStateIndex
val index = output.int
return convert.index2Word(index)
}
如此一来,通过重复调用 fetchNext 输入一个文字,最终连成一首诗。需要注意的是第一个输入的字符必须是 “<START>”,告诉模型开始作诗了,代码参考 AiPoet.song(…)
 |
1
dcalsky 2020-02-17 18:08:07 +08:00
cool
|
 |
2
leetao94 2020-02-17 18:41:39 +08:00
赞👍~要是用 pytorch 写的就更好了
|
 |
3
SteveZou 2020-02-17 18:52:55 +08:00 via Android
强
|