
这是一个创建于 1621 天前的主题,其中的信息可能已经有所发展或是发生改变。
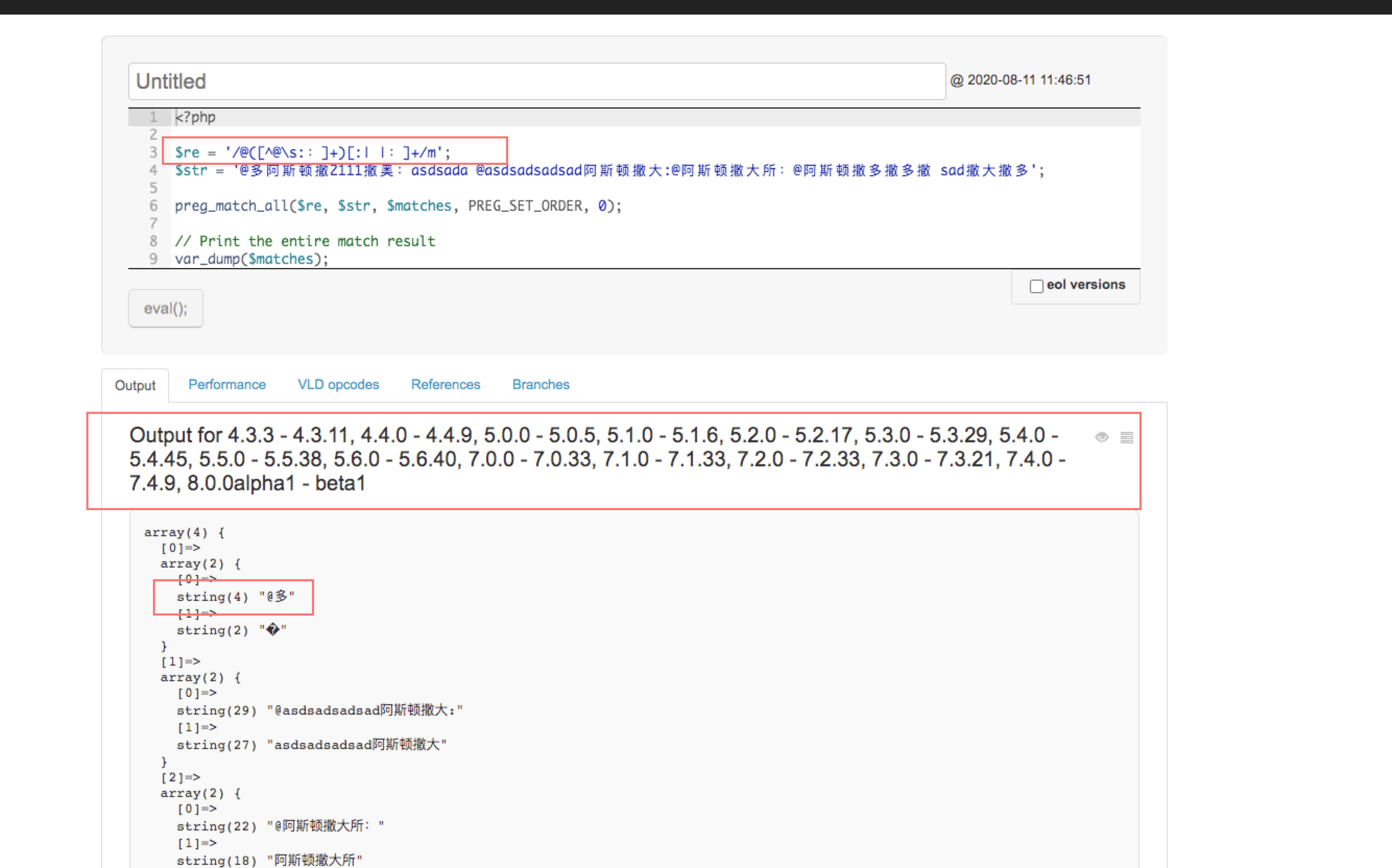
$re = '/@([^@\s::]+)[:| |:]+/m';
$str = '@多阿斯顿撒 2111 撒奥:asdsada @asdsadsadsad 阿斯顿撒大:@阿斯顿撒大所:@阿斯顿撒多撒多撒 sad 撒大撒多';
preg_match_all($re, $str, $matches, PREG_SET_ORDER, 0);
// Print the entire match result
var_dump($matches);
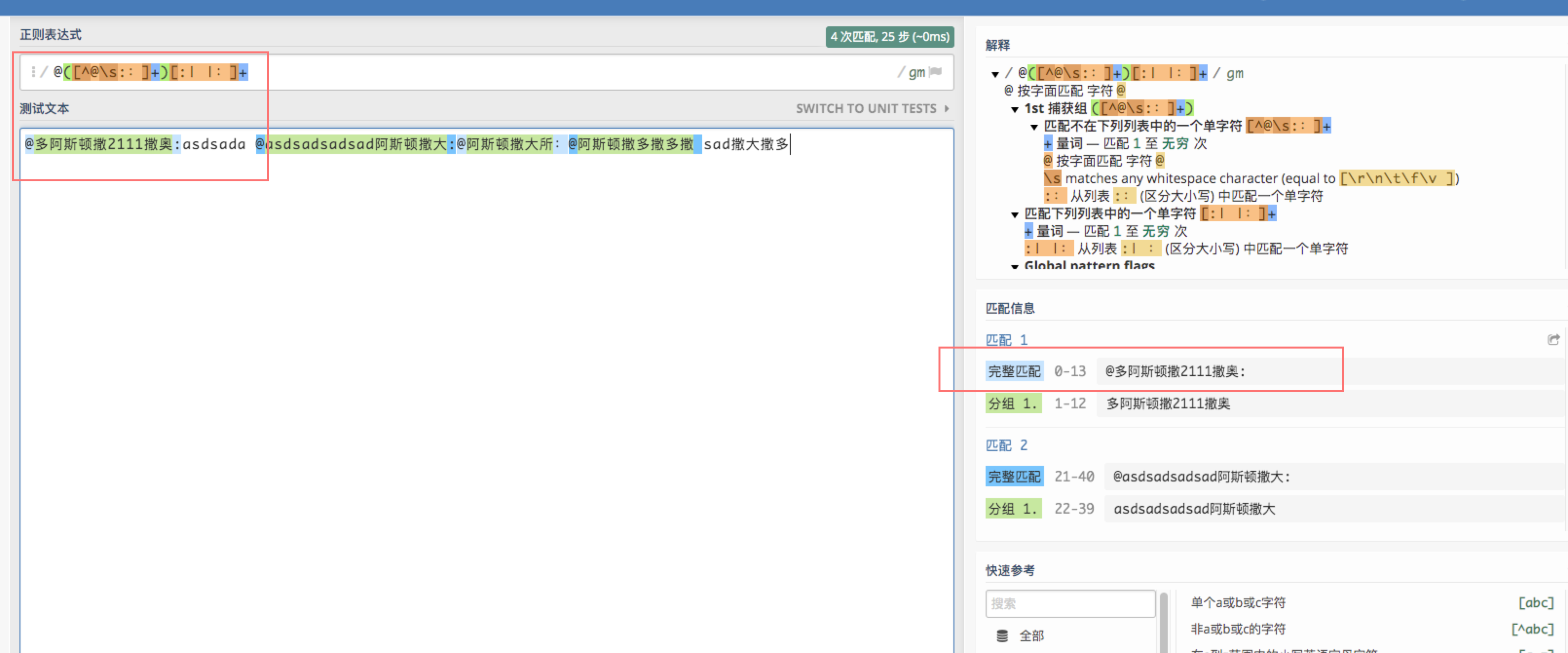
测试了下所有版本的 php 解析的结果都是错误的,其他语言 Python,Js 等可以正常解析。
错误的结果
正确的解析结果
 |
1
gz911122 2020-08-11 13:20:47 +08:00
截图的那个正则网站是啥, 看起来不错啊
|

 |
3
CismonX 2020-08-11 13:59:11 +08:00 这个是引擎不识别 unicode 字符的问题。改成:
$re = '/(*UTF8)@([^@\s::]+)[:| |:]+/m'; 就没问题了。 |
 |
4
iyaozhen 2020-08-11 14:45:25 +08:00 不要见风就是雨
/u 才能识别中文 |
 |
5
vc1 2020-08-11 18:12:42 +08:00
执行 php 代码的图是哪个网站
|
