
这是一个创建于 1504 天前的主题,其中的信息可能已经有所发展或是发生改变。
9 月 19 日,CODING 和中国 DevOps 社区联合举办的深圳第九届 Meetup 在腾讯大厦 2 楼多功能圆满结束。本次沙龙以 「 DevOps 转型与实践」 为主题,4 位来自互联网、金融、零售行业的知名世界 500 强企业技术大咖,在现场分享了他们对于 DevOps 转型实践的见解和经验。80 多位观众与讲师们也进行了深入的技术探讨,共同探讨在 DevOps 潮流下,企业可能面临的新机遇和挑战。

CODING 一直致力于让所有开发者都能有机会倾听最具前沿的 DevOps 技术分享,之后还会在全国各地举办一系列 DevOps 技术沙龙。在不同城市的小伙伴也无需担心,我们届时会提供线上直播平台,让异地的同学也能与导师无障碍交流,敬请期待!话不多说,本期为大家分享的是 《 DevOps 在 SEE 小电铺的落地与实践》——
背景介绍
SEE 小电铺是微信生态内最大的小程序电商服务平台,目前累计与 10000+ 自媒体合作开店,是微博、斗鱼等平台的官方电商 SaaS 服务商,以及抖音头部渠道电商平台。
SEE 小电铺技术负责人马志雄讲述了在竞争激烈的电商行业背景下,SEE 小电铺是如何引入业界优秀的 DevOps 实践,打造了高效稳定的应用交付体系,帮助公司迈向云原生时代的。他主要围绕落地的法则,分享了 SEE 小电铺内 DevOps 实践的目标、落地的原则和具体实践。
引入 DevOps 实践
在疫情期间,SEE 小电铺的工作人员采取了远程办公模式,这对所有人的协作和效率提出了更高的要求。研发流程中出现的各种问题促使 SEE 小电铺反思技术架构、研发流程、度量工具以及团队文化如何能够高质量地顺畅交付用户价值。
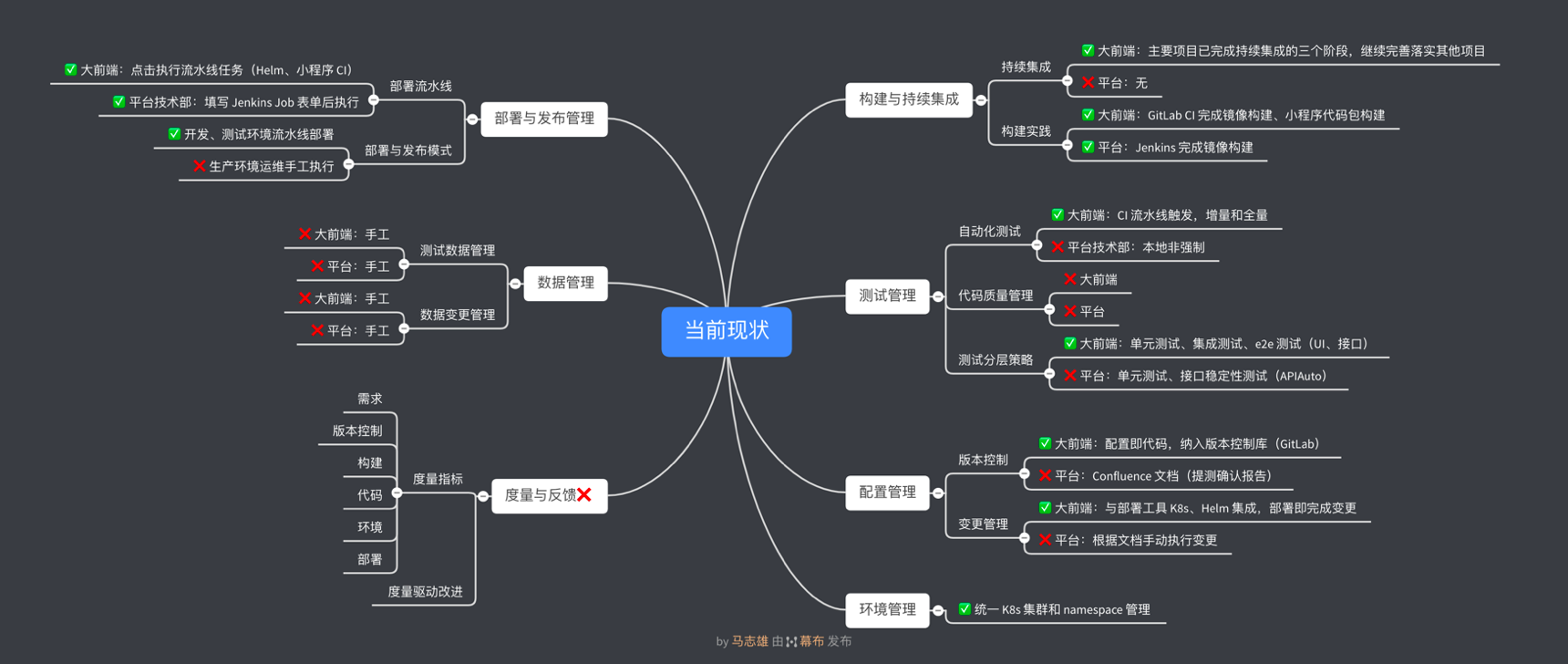
**持续改革的第一步是识别问题。**经过调研和讨论,SEE 小电铺首先引入了 DevOps 能力成熟度模型,对当前团队里面存在的问题以及需要补齐的能力进行梳理。
SEE 小电铺在组织支撑方面设立了 DevOps 工作小组,由工程效能团队专项推进,把 DevOps 具体事项纳入 OKR 里进行目标管理,并拆解到相关的一线同事里面去。借此机会,团队文化被重新塑造,工作小组不断和一线同事讲未来的技术方向是什么,为什么要去做这件事情,和所有人同步推进 DevOps 目标、方法和策略。在具体落地路径上,灰度思维帮助优先主导推进那些对 DevOps 认同度比较高的同事,从比较容易改造并且能够迅速看到成效的项目着手。
随后,SEE 小电铺制定了一期改进目标:
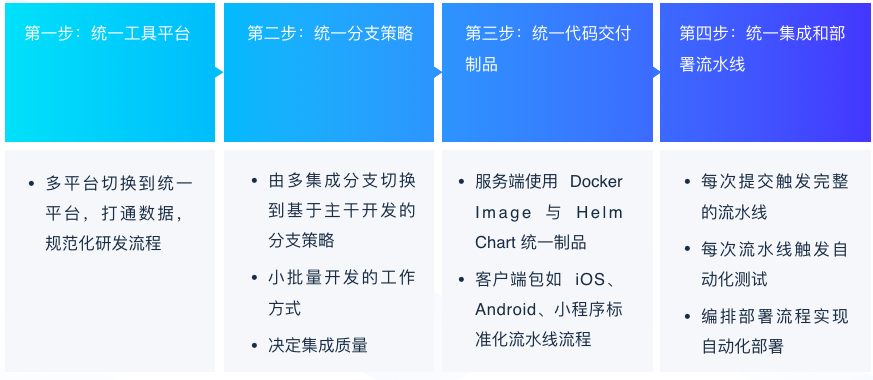
- 统一工具平台
过去 SEE 小电铺使用了繁多的工具,不仅有维护成本高等问题,在实际研发过程中的使用也不太顺畅。举个例子,部署还是依赖于人工 + 脚本的方式手动进行。在调研了市面上各种 DevOps 工具,最终 SEE 小电铺选择了 CODING DevOps 作为一站式研发平台。主要的优势体现在不需要跳转多个产品,整个数据是打通互联的,而且部署在国内,访问速度好,中文支持度高,团队成员上手也比较快。另外,持续部署是基于 Spinnaker,功能比较强大,和目前使用的腾讯云集成较好。测试管理也无需单独付费,整个维护无需自建维护,性价比高。
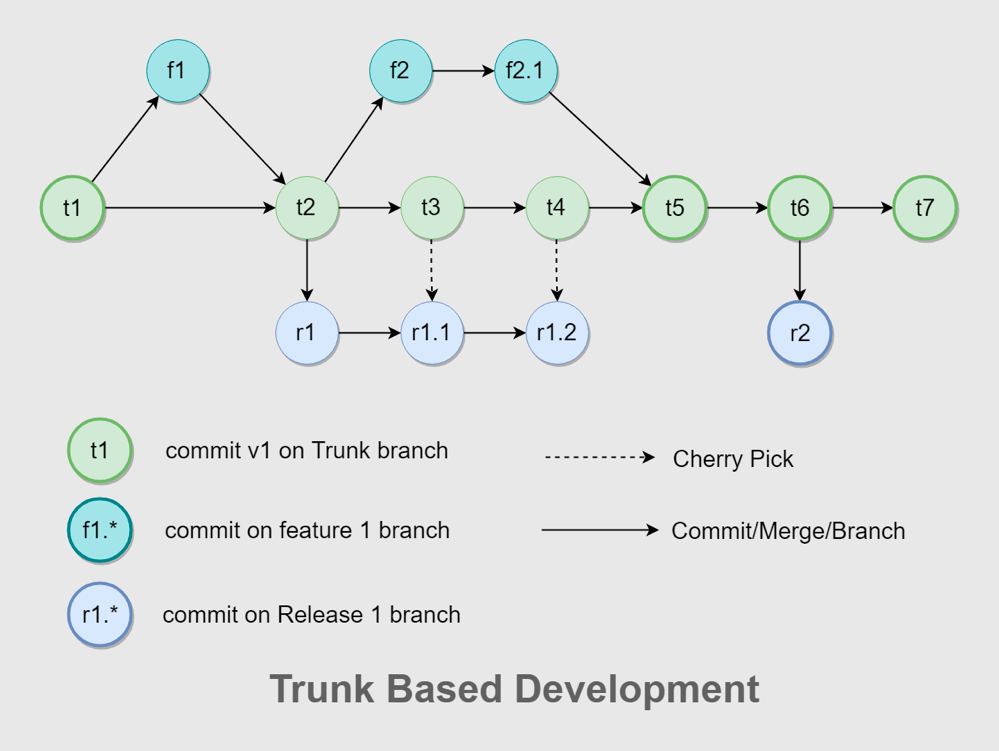
- 统一分支策略
在工具切换之后,SEE 小电铺面临的一个困境是分支策略不统一。GitLab Flow 和 Git Flow 混合使用,整个流程非常复杂,容易出错,合并也非常费时。多个版本并行时,GitLab Flow 需要配套多个环境,与持续集成的理念相违背。为了把研发效能提升到比较极致的状态,SEE 小电铺结合团队自身的情况,决定采用有功能分支的主干开发策略,然后在团队内部不断地去讲怎么用,包括怎么去更好地拆用户故事和任务,怎么去做 git cherry-pick 和 rebase,怎么去把 commit 设计得更加原子性等。
- 统一制品管理
SEE 小电铺之前面临的制品管理困境是应用的分发包是多种多样的:整个系统在经过微服务进行改造以后,累计有四五十个服务需要进行维护,面临着多应用集合管理和配置困难的问题;另外制品库也是不统一的,缺乏统一的管控以及权限控制。在这种情况下,SEE 小店铺使用了 Docker 和 Helm 来解决制品的统一性问题。Docker 镜像能够标准化交付元件,Helm 能够帮助简化 K8s 资源集合管理和配置,并且方便回滚和更新。制品库则统一迁移到 CODING 制品库来做制品托管,实现应用制品的单一来源管控以及细粒度的权限控制。
- 统一集成和部署流水线
经过多年的业务发展,SEE 小电铺的应用数量非常多,缺乏体系化的流水线建设。少部分比较完善的项目工程使用 GitLab CI,还有一部分用 Jenkins 来做构建打包,大部分的应用还在使用 shell 脚本拉取 jar 包进行发布,已有的自动化部署耦合在 CI 里,环境与配置复杂以后难以维护,不够规范且效率低容易出错。因此 SEE 小电铺首先制定了 CI 流水线的规范,包括根据不同的技术栈设计符合的流水线流程,根据分支模型和 MR 流程划分全量集成和增量集成,以及各个流程的耗时标准;之后把工具统一切换到 CODING 支持的 Jenkins,做好构建节点的资源规划,确保每次流水线都会触发自动化测试,包括代码格式检查,代码规范和静态分析,以及单元测试、集成测试和 E2E 测试的自动化执行。最终执行的一个结果会通过企微机器人同步到专门的工作群。
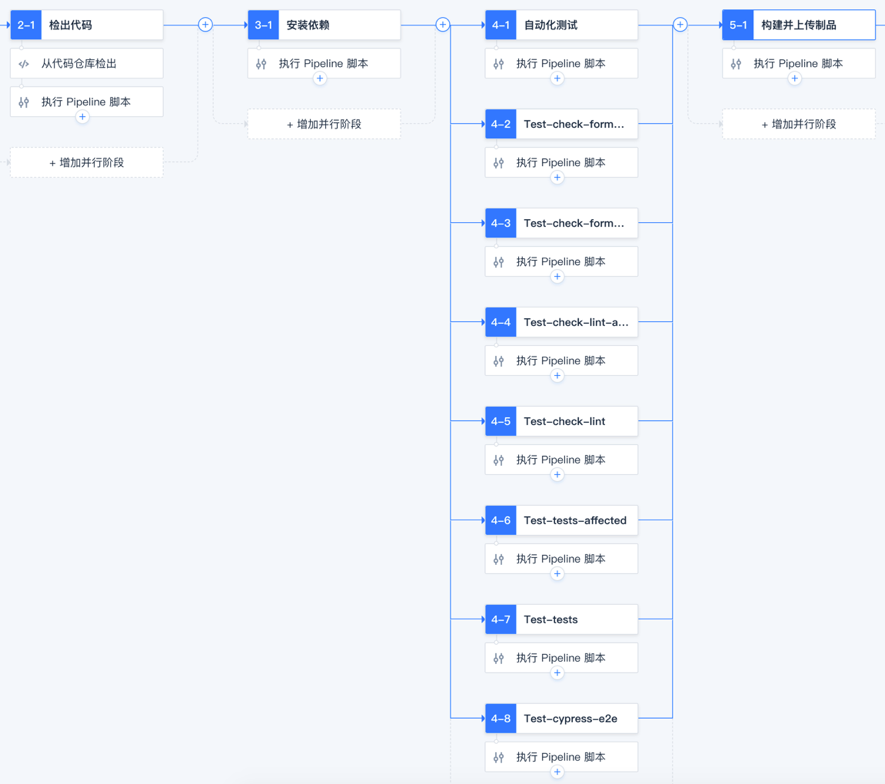
持续部署的流水线设计,主要是借助 Spinnaker 来进行编排,配置好 Bake 和部署流程,这里面的交付制品统一使用 Helm Chart,并且借助 CODING 的持续部署功能来进行发布单的管理,包括创建提单,并行部署,人工审批等。
云原生基础架构
除了以上这四步以外,SEE 小电铺的 DevOps 实践还贯穿了很多其他理念。首先在基础架构方面,SEE 小电铺贯彻云原生的理念,把整个应用进行了 K8s 容器改造,直接使用腾讯云 TKE 产品来托管集群,帮助快速完成容器化改造,进行微服务和 BFF 架构风格下的高效容器编排,实现应用的标准化交付,确保资源隔离性和高效的利用率,并能保证环境的一致性。同时在面对流量潮汐时,也能够基于 HPA 和 Cluster AutoScaler 实现 Pod 和节点灵活快速的扩缩容,从容应对业务的各种活动和大促。同时借助 K8s 的 Readiness Probe 和 Liveness Probe,能够比较好地实现服务的自愈和容错。在把 K8s 引入基础架构以后,SEE 小电铺通过引入服务网格技术 Service Mesh 实现了更加精细化的服务治理。通过 Istio 服务治理中核心的 Virtual Service 和 Destination Rules 这两个 CRD 结合 CODING 的持续部署可以实现自动化灰度发布,取代原有的集群蓝绿发布策略,把资源利用和流量控制做到一个相对比较极致的水平,并且把微服务架构里难以落地的服务治理固化成了一个标准的基础设施,让开发能够更加关注应用本身。
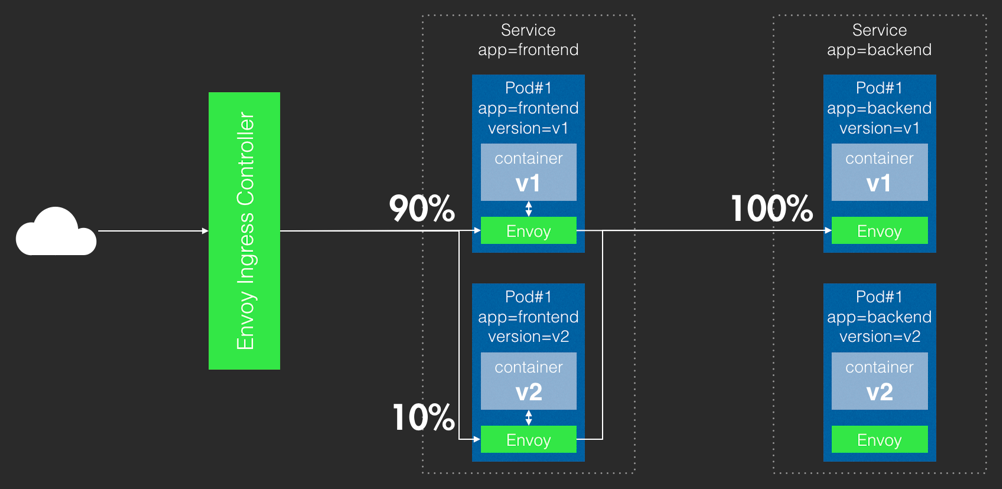
在上图中,根据 Istio 里面的配置规则可以实现按百分比把 10% 的流量打到新的应用里,最终通过校验以后可以把整个流量进行完全切换,实现精细化的流量转移。
可靠性 & 可观测性
SRE 方法论被 SEE 小电铺引入指导可靠性建设。首先,SLO 可靠性建模包括三个维度:Availability 可用性、Latency 延迟和 Ticket 人工干预。这三个维度分别对前后端应用进行了白盒和黑盒监控指标采集,模型计算公式最终可以输出整个服务指标。SRE 团队基于此模型搭建了内部所有服务的可靠性看板,能够实时对生产环境的服务可靠性指标进行查看和跟进。SRE 方法论中还有一个非常好的概念,就是错误预算。基于 SLO 的模型,可以计算出一段周期内错误预算消耗了多少,从而决定是否调整这个周期内的版本发布频率以及节奏。比如说要维持 99.9% 的可靠性,那一个月内的不可用窗口期就是 43.2 分钟。
可观测性基于 EFK 日志平台做了所有服务的日志收集与聚合,帮助做 K8s 改造后所有容器的收集;指标监控方面基于 Prometheus 和 Grafana 搭建了监控平台,帮助进行发布盯盘和对 Pod 异常指标进行记录和告警。
质量内建
质量内建方面,SEE 小电铺遵循了一些 DevOps 社区内较为流行的原则来实施。首先是质量门禁,内部的指标所有单元测试模块覆盖率都必须大于 80%,老的系统也会在项目排期里面不断补充完善,web 、小程序、iOS 、Android 和 React Native 等应用要求要有 100% 的 E2E 测试来覆盖所有的应用场景,质量门禁还需要管控合并请求,开发的 MR 需要通过 CI 自动化测试,CODING 远程提供的代码静态扫描以及结对代码 Review 以后才会被合并到主干。其次,CODING 的测试管理成功将 SEE 小电铺从原始的 Excel 管理测试用例中解放出来,支持用例的在线评审并制定迭代的测试计划。DogFooding 自测允许在集成环境上进行冒烟测试,通过测试管理中的测试计划进行追踪,并组织提测前的 demo 演示。
成果
在半年多的 DevOps 变革和实践里,SEE 小电铺实现了多项核心指标提升,单个服务部署时长从以前的数小时缩短到 5 分钟,总的全量环境部署也从一两个星期缩短到 1 个小时,开发 bug 率下降了 10 倍左右。调整迭代规划以后,大概达到每周 2 次全量环境部署频率,变更前置时间也缩短到 1 周以内,可用性也达到了 99.9%。更重要的是,团队更加聚焦到了业务交付本身。
Q:Helm Chart 管理的资源很多,你们在这方面有没有最佳实践?
A:我们做了很粗暴的一刀切,前端的应用是公共的 Helm Chart,后端的应用是另外一个 Chart,各个服务作为 Chart 中的子应用,是 Chart 里面的其中一块。在内部工程效能组规范化以后,所有的应用都是按照这个模板来做的。
Q:请问你们团队是怎么保证发布后的质量的?
A:我们的可用性维持在 99.9% 左右,但难免还是会有泄露的 bug,我们要在业务创新和稳定性中取得权衡,这个权衡就是通过 SLO 的方式。我们通过确保整体的服务维持在 99.9% 的可靠性目标前提下,尽可能快地去发布我们的应用。
温馨提示:
更多讲师 PPT 及演讲稿脱敏后将逐步更新
点击开启 CODING DevOps 云上研发工作流
目前尚无回复