
求助一条 SQL 语句的写法,分组查询,求每个学生第一次考试成绩和最后一次考试成绩的差值
LeeReamond · 2020-12-29 19:04:17 +08:00 · 1777 次点击这是一个创建于 1561 天前的主题,其中的信息可能已经有所发展或是发生改变。
目前有一表如下,共三列
学生 ID 考试时间 成绩
0 2020-01-01 60
0 2020-02-01 70
0 2020-03-01 80
1 2020-02-14 90
1 2020-03-15 80
想要执行一条语句搜索,得到如下结果
学生 ID 第一次成绩 最后一次成绩 差值
0 60 80 20
1 90 80 -10
也就是想要通过 group by 根据学生 ID 进行分组,之后取出某组中的初次和末次。 平台 Oracle,看了一下 Oracle 分组查询的教学,似乎 Oracle 分组里面只有 max,min,avg 之类的函数 没有办法按顺序取某条某条吗?有没有大佬讲解一下,谢谢
 |
1
kiracyan 2020-12-29 19:16:26 +08:00
order by 考试时间
|
 |
2
loliordie 2020-12-29 19:18:31 +08:00 via Android
Order by 考试时间 和 order by 考试时间 desc 组合起来即可
|
 |
3
zm8m93Q1e5otOC69 2020-12-29 19:20:06 +08:00
mysql 的话我想是 按照时间 asc desc 然后 limit 1 ? 两个结果 union all 一下?。。Oracle 没用过。。
|
 |
4
LeeReamond OP |
 |
5
loading 2020-12-29 20:42:59 +08:00 via Android
最好说一下是哪型数据库,有特殊语法。
|
|
6
loading 2020-12-29 20:43:31 +08:00 via Android
oracle 要用 row number 吧
|
 |
7
qiayue 2020-12-29 21:15:31 +08:00 有一个特别简单的办法,用户表加两个字段,首次考试分数和最后一次考试分数,实际产品中,这是最佳解法
|
 |
8
yeqizhang 2020-12-29 22:18:02 +08:00 via Android
楼主自己找到解法的话分享一下哈,我也学习学习
|
 |
9
l00t 2020-12-29 23:04:28 +08:00 多年不写有些具体的忘记了,我就提几个关键字,楼主你自己去查一下补全吧。
first_value(成绩)over(partition by ID order by 时间), last_value(成绩)over(partition by ID order by 时间) |
|
10
LeeReamond OP @l00t 感谢大佬,成功实现了。不过这个我做出来的结果是,比如源数据库共有两种学生 ID,那么我期望输出两行,但是他实际输出的行数与考试次数相等,然后每一行数据都一样,这种结果出来怎么处理?
进行 group by 吗?感觉又浪费了一次算力。生产的最佳实践是什么? |
 |
11
dzdh 2020-12-30 00:38:57 +08:00
@LeeReamond 最佳实践看#7
|
|
12
l00t 2020-12-30 08:17:47 +08:00
@LeeReamond #10 加个 distinct
|
 |
13
isnullstring 2020-12-30 08:32:46 +08:00
@qiayue 哈哈哈,没有比静态数据来更快的解法
|
 |
14
ebony0319 2020-12-30 09:40:34 +08:00
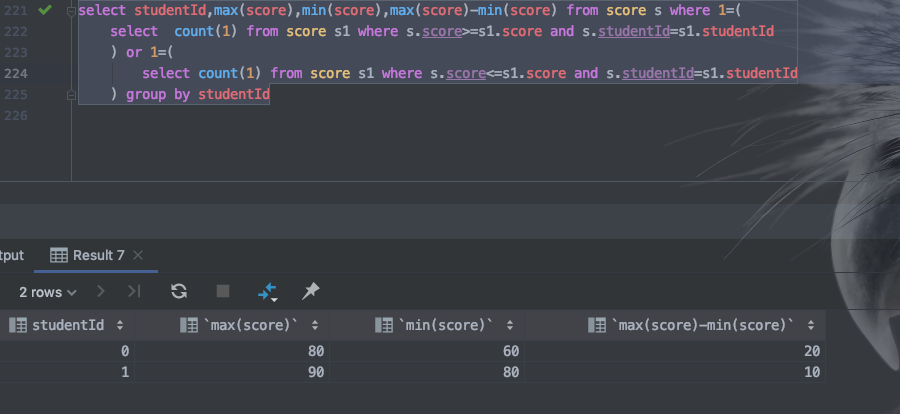
select studentId,max(score),min(score),max(score)-min(score) from score s where 1=(
select count(1) from score s1 where s.score>=s1.score and s.studentId=s1.studentId ) or 1=( select count(1) from score s1 where s.score<=s1.score and s.studentId=s1.studentId ) group by studentId |
|
15
ebony0319 2020-12-30 09:42:05 +08:00
[]( https://imgchr.com/i/rqRyNj)
|
|
16
ebony0319 2020-12-30 09:44:21 +08:00
抱歉,审错题了.我是按照最高分,最低分来写的.吧里面的条件改成 s.time>=s1.time 即可
|
 |
19
isir1234 2020-12-30 15:15:34 +08:00
select student_id, gap
from (select student_id, last_value(score) over (partition by student_id order by created_at) - first_value(score) over (partition by student_id order by created_at) AS gap, row_number() over (partition by student_id order by created_at desc) rn from exam) tmp where rn = 1; |