
这是一个创建于 1188 天前的主题,其中的信息可能已经有所发展或是发生改变。
GNE 是一个通用的新闻正文抽取器,自从两年前我在 V2EX 首发开源以来,已经被很多人用来作为新闻正文通用爬虫的重要组件。
使用 GNE,不需要配置任何规则,就能够自动化提取新闻的正文:
>>> from gne import GeneralNewsExtractor
>>> html = '''经过渲染的网页 HTML 代码'''
>>> extractor = GeneralNewsExtractor()
>>> result = extractor.extract(html)
>>> print(result)
{"title": "xxxx", "publish_time": "2019-09-10 11:12:13", "author": "yyy", "content": "zzzz", "images": ["/xxx.jpg", "/yyy.png"]}
GNE 的 Github 地址:https://github.com/GeneralNewsExtractor/GeneralNewsExtractor。算法来自论文于《基于文本及符号密度的网页正文提取方法》,这个算法是完全基于 HTML 里面的信息来寻找正文。因此,它有一些先天性缺陷:
- 如果正文只有三五句话,但评论是长篇大论,提取就会失败
- 如果正文里面 html 标签太多,也会导致正文找错位置
- 经常提取到版权信息
但如果让人来看网页,就不会搞错。因为正文的位置和评论的位置肯定不一样,版权信息一般在最下面……这些可视化信号,是通过 CSS 来确定的,单纯从 HTML 中是看不到的。
GNE 输入的 HTML,原本就是使用模拟浏览器输出的 HTML,并不是真正的网页源代码。既然如此,在使用模拟浏览器的时候,为什么不直接把每个节点的坐标信息都记录下来呢?在使用模拟浏览器的时候,只需要执行一段 JavaScript 代码,就可以把每个节点是否可见,每个可见节点的长宽高、左上角、右下角的坐标记录下来。这样,GNE 在解析正文的时候,可以参考这些信息,直接移除不可见的节点,并移除尺寸显然不合理、位置显然不正确的节点。从而大大提高正文识别的准确率。
基于可视化信号的提取效果如何呢?我们用一篇新闻来作为例子:广西省发生了一起事件,位置在来宾市,画面曝光。
首先在浏览器的开发者工具里面,直接复制经过 js 渲染后的源代码:
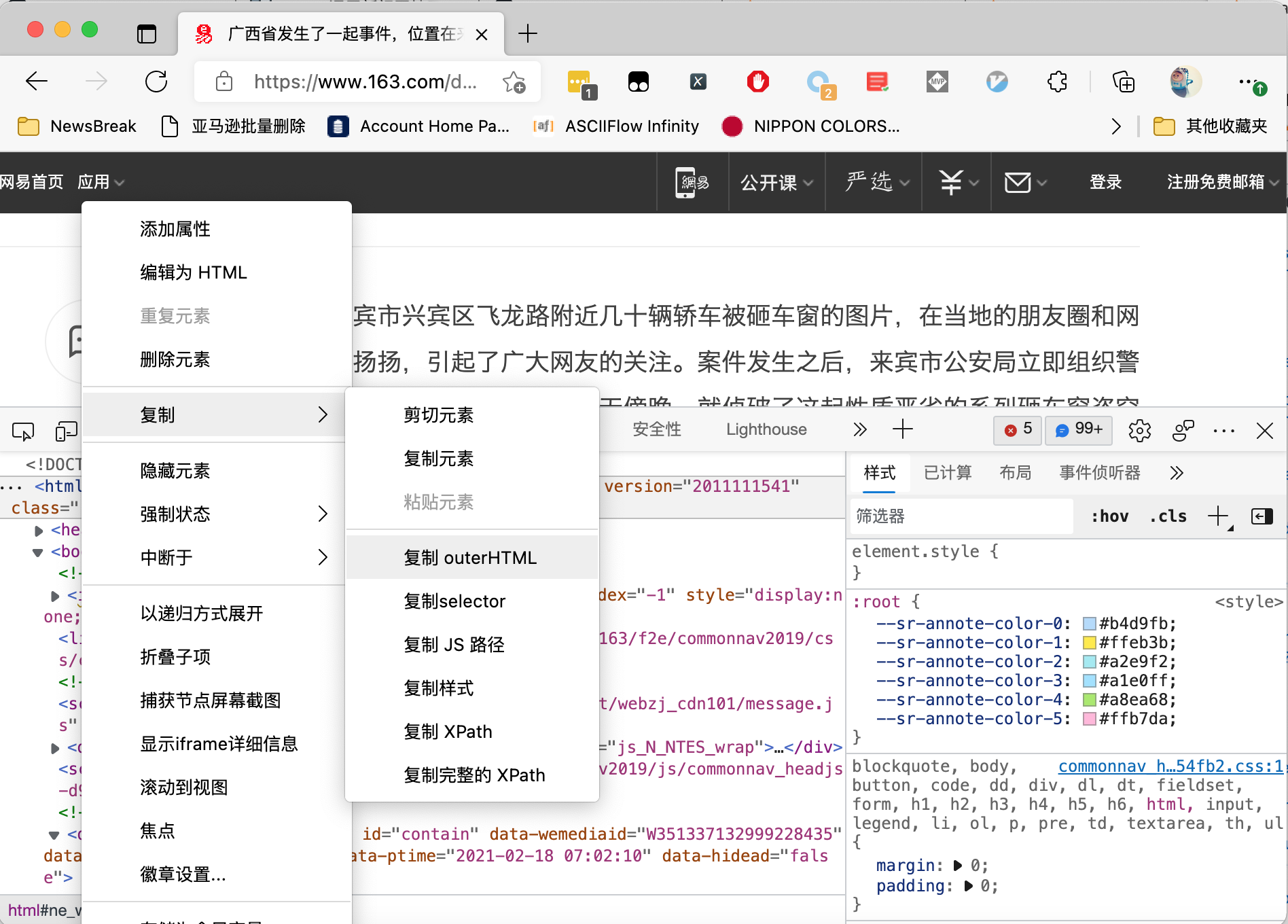
当我们直接使用 GNE 识别正文的时候,运行效果如下图所示:

可以看到,提取到的信息是版权信息。
现在,如果使用经过修改的 HTML 代码,就能成功提取到正文,如下图所示:
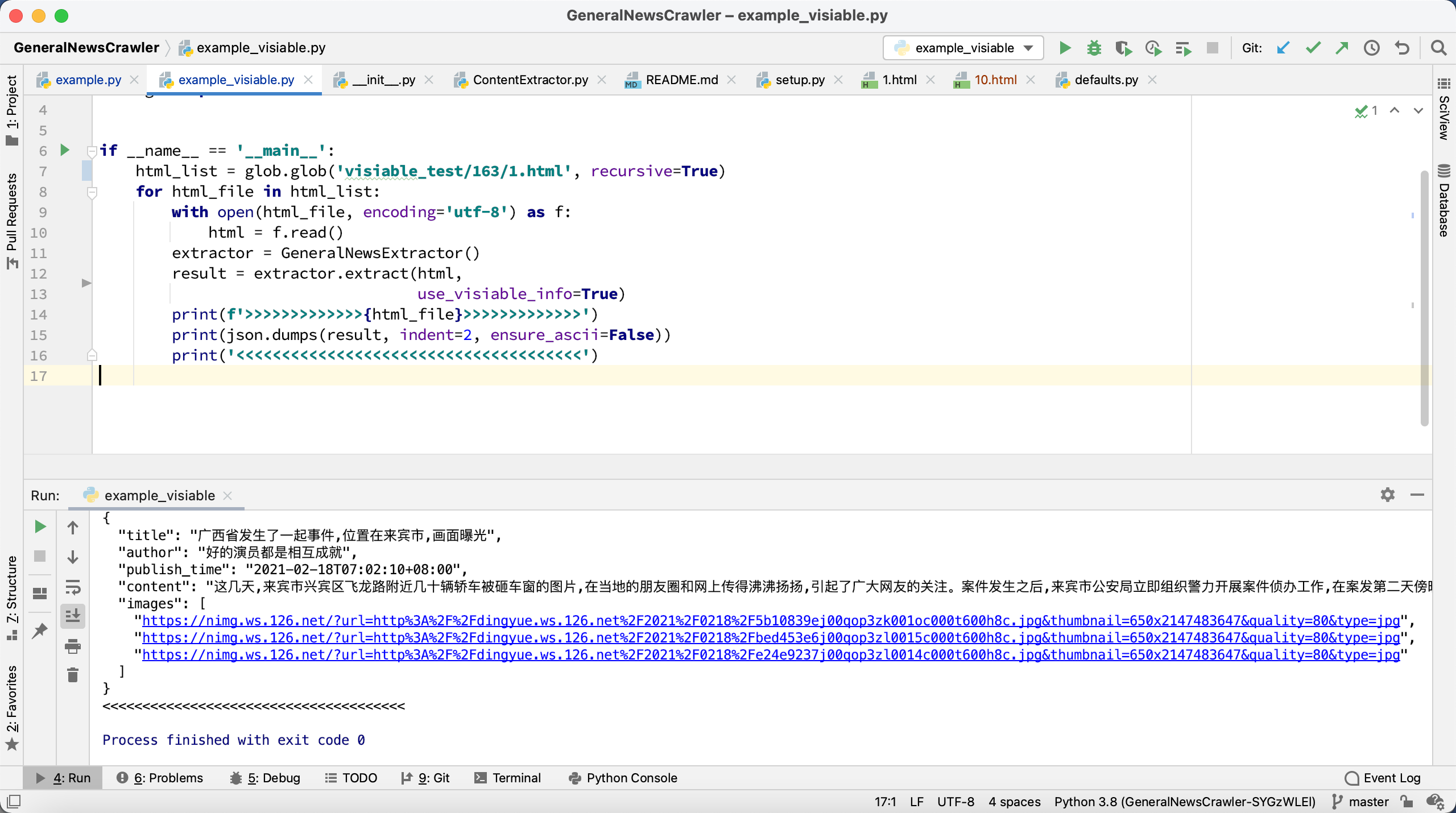
那么,这个经过修改的 HTML 有什么特别呢?我们来看看它长什么样:
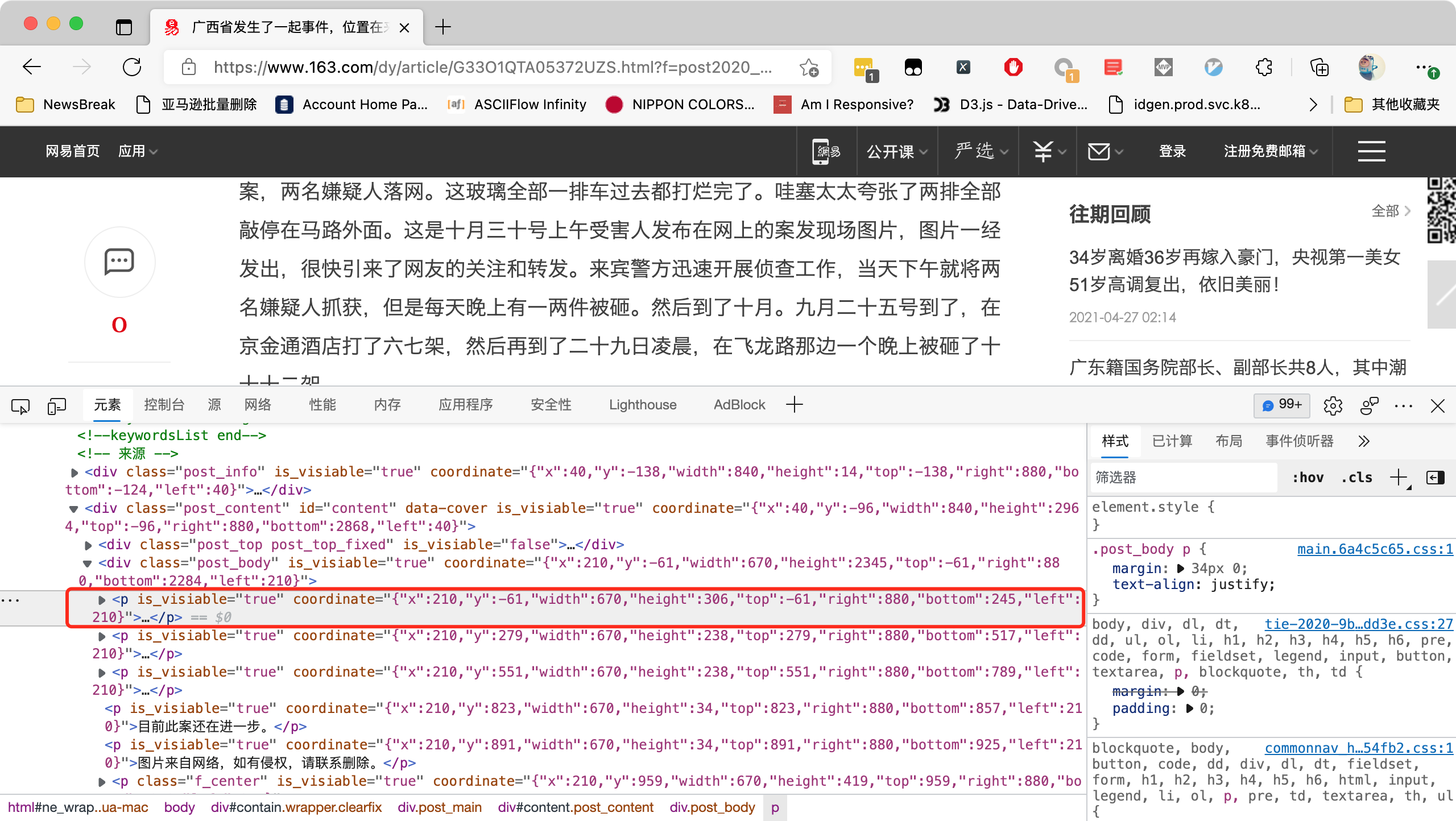
在body 标签下面的所有节点,都有一个属性叫做 is_visiable ,它的值是字符串的 true 或者 false 。如果值为 true ,
那么,还有一个属性叫做 coordinate 。它的值是一个 JSON 字符串,包含了这个节点的尺寸,坐标等信息。
那么,这些特殊的 HTML 是怎么生成的呢?如果你只是想做一个临时测试,那么其实只需要在 Chrome 的开发者工具的Console(控制台)标签页执行这样一段 js 代码就可以了:
function insert_visiability_info() {
function get_body() {
var body = document.getElementsByTagName('body')[0]
return body
}
function insert_info(element) {
is_visiable = element.offsetParent !== null
element.setAttribute('is_visiable', is_visiable)
if (is_visiable) {
react = element.getBoundingClientRect()
coordinate = JSON.stringify(react)
element.setAttribute('coordinate', coordinate)
}
}
function iter_node(node) {
children = node.children
insert_info(node)
if (children.length !== 0) {
for(const element of children) {
iter_node(element)
}
}
}
function sizes() {
let contentWidth = [...document.body.children].reduce(
(a, el) => Math.max(a, el.getBoundingClientRect().right), 0)
- document.body.getBoundingClientRect().x;
return {
windowWidth: document.documentElement.clientWidth,
windowHeight: document.documentElement.clientHeight,
pageWidth: Math.min(document.body.scrollWidth, contentWidth),
pageHeight: document.body.scrollHeight,
screenWidth: window.screen.width,
screenHeight: window.screen.height,
pageX: document.body.getBoundingClientRect().x,
pageY: document.body.getBoundingClientRect().y,
screenX: -window.screenX,
screenY: -window.screenY - (window.outerHeight-window.innerHeight),
}
}
function insert_page_info() {
page_info = sizes()
node = document.createElement('meta')
node.setAttribute('name', 'page_visiability_info')
node.setAttribute('page_info', JSON.stringify(page_info))
document.getElementsByTagName('head')[0].appendChild(node)
}
insert_page_info()
body = get_body()
iter_node(body)
}
insert_visiability_info()
如下图所示:

执行完成以后,重新打开Elements(元素)标签页,就可以看到我们需要的属性已经添加到了各个节点里面。
如果你想要使用 Puppeteer 或者 Selenium 来实现同样爬虫,想批量自动化执行 JavaScript,我给出一个 Demo,大家可以参考:GitHub - GeneralNewsExtractor/GneRender: Render web page to add necessary info on every dom element..
只需要执行如下几个命令:
yarn install
node render.js
就可以在当前文件夹下面生成一个test.html,就这是经过修改的特殊 HTML 了。
最新版本的 GNE 已经提交到了 Pypi,大家现在可以直接试用 pip 安装:
pip install gne
 |
1
mosliu 2021-10-07 23:33:44 +08:00
看上去很好 明天试试
|
 |
2
Echoldman 2021-10-07 23:38:05 +08:00
请教楼主一个问题,既然可以通过文本符号密度来识别正文,那能不能通过“关键词”、“符号”来识别代码呢?
|
 |
3
mekingname OP @Echoldman 论文里面是文本密度加上标点符号密度。标点符号是要纳入考虑的。
|
|
4
mekingname OP @mosliu 你试一试就会发现很好用。
|
|
5
mosliu 2021-10-08 17:33:16 +08:00
@mekingname
看了看 是 MIT 协议 可以直接商用么? |
|
6
mekingname OP @mosliu 可以。
|
|
7
mekingname OP @mosliu 但衍生产品必须开源,并也使用 MIT 协议。
|
 |
8
2i2Re2PLMaDnghL 2021-10-11 15:25:54 +08:00
@mekingname 我又冒出来谈许可证了,你这个额外要求不符合 MIT 许可证之明确授权,MIT 授权的责任要求只限保留署名和 MIT 许可证文本两项。
|
 |
9
jeremaihloo 2021-10-11 17:35:12 +08:00
@mekingname 你使用了 MIT,那么别人几乎可以随便使用,不需要满足衍生产品必须开源的要求,建议换一个开源协议
|
|
10
mekingname OP |