
这是一个创建于 1094 天前的主题,其中的信息可能已经有所发展或是发生改变。
最近想加深一下对 CPU core 之间的缓存同步,内存模型的理解,读了一些文章。在此之前,我知道除了编译器以外,多核 CPU 也是可以对指令进行重排的,比如下图中两个核心的指令,如果没有重排的话,r1 == 0 && r2 == 0是不可能发生的,

实际情况下,CPU 是可以把指令重排成如下顺序,以至于r1 == 0 && r2 == 0是可能发生的,
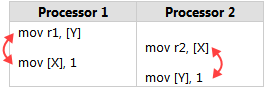
但标准又说了,在单核的情况下,这种重排是不可能发生的。由此我联想到了 MESI 协议,CPU 在不同核之间,MESI 协议保证了缓存生效 /失效。
请问是否可以这么理解,CPU 某个核心上的指令重排现象(上图 CPU2 上)是否只是因为 MESI 消息太慢导致的的表征?实际上 CPU2 还是按照既定的指令顺序执行,还是说 CPU2 真的就是调换了两个指令的顺序呢?
第 1 条附言 · 2022-04-09 00:23:09 +08:00
抱歉各位,我不知道 reorder 在不同语境下要分别翻译成“重排”和“乱序”
 |
1
mxT52CRuqR6o5 2022-04-08 17:11:09 +08:00
CPU 层面叫乱序执行吧,指令重排是编译器层面的
|
 |
2
katsusan 2022-04-08 17:23:33 +08:00 via iPhone
Load 会 stall 但 store 不会
|
 |
3
cubecube 2022-04-08 17:27:29 +08:00
不能这么理解,没有任何联系。
CPU 乱序和重排是主动的,不是被迫 |
 |
5
bigdoing 2022-04-08 17:31:38 +08:00 via iPhone
一顿胡扯
跟粘包有得一拼 |

 |
7
FrankHB 2022-04-08 18:16:50 +08:00 哪个标准说了单核了……
C 和 C++之类的单线程 sequence before 完全是严格按照抽象机语义体现“;”这样的语法构造的语义。 而 CPU 实际上不保证存在这种顺序。 尽管原则译码的指令流是(按程序序)顺序的(用 PC 或者 IP 之类的架构寄存器的值保存),发射和执行从来就不需要保证严格的顺序。 乱序执行在核心内部实现,单核自然也可以发生这种所谓的重排序。这时候完全不需要关心核之间通信的 MESI (虽然可以复用 MESI 这样的 uncore 协议,但除了凭空复杂以外没什么用)。 特别地,对现在的执行单元来说,它可见的是解码之后的结果即微指令构成的信号,而不需要是架构支持的 ISA 指令,后者甚至根本不保证是乱序程序的输入——有些指令根本不需要进入 CPU 的执行单元(如 Intel SnB 等的 xor zeroing ;尽管抽象上这仍然叫“执行”,因为指令被消费掉了,区分于不管输入死活的“运行”)。所谓重排的结果只是和这种微程序尽量相同的以 ISA 指令重新实现的描述。 根本上,重排也就是为了叙述方便,指出和指令流基准的默认序(程序序)不同的部分而已。(算上投机执行,任一分支路径跳转也能算基准之内。)然而你没理解清楚乱序的来源,那么这种方式就是无益的。 |
 |
8
heiher 2022-04-08 19:45:34 +08:00 via Android
即使是单核 CPU 也可乱序执行,乱序执行能提高多部件利用效率,避免资源访问延迟产生的空等等等,cache 一致性维护开销产生的延迟当然也是一个因素之一,但并非全部。只是并行的多核(多读端)能观察到乱序而已。
|
|
9
heiher 2022-04-08 19:53:17 +08:00 via Android
再补充一点,store buffer 和 cache invalidate queue 也是产生访存乱序效果的因素之一,这两导致访存乱序效果是可以在读端和写端都按序执行的情况下。
|
 |
10
Caturra 2022-04-08 20:13:20 +08:00
MESI 跟重排(乱序执行)有啥关系,我感觉不是同一层面的东西
我觉得楼主说的意思应该是:CPU 嫌弃 MESI 维持 cache 一致性的过程太慢从而影响了乱序执行的决策? 这可能要知道乱序执行是怎么具体实现的了(只了解过 x86 这种差不多是 program order 套个 W->R 乱序),蹲个大佬 |
 |
11
secondwtq 2022-04-08 22:13:44 +08:00
去把《 Memory Barriers: a Hardware View for Software Hackers 》这篇文章看一遍
|
 |
12
dahakawang 2022-04-08 23:22:29 +08:00 这个和缓存的一致性协议(e.g. MESI)没有关系,主要是和 x86 的内存一致性模型的约定有关。
为了实现的简便,或者优化的方便,计算机领域一个非常重要的 trick 就是[as if rule]( https://en.wikipedia.org/wiki/As-if_rule)。编译器和硬件可以不按照实际的程序 /指令执行,只要最终不会产生**软件可以观察到**的差异就行了。 具体来看,如果我们更多的在聊 Intel 的话,x86-TSO 的内存一致性模型主要有下面这么几个约定,而 OP 的例子正是很多人用来说明第 4 点的比较常用的例子: 1. Loads are not reordered with other loads. 2. Stores are not reordered with other stores. 3. Stores are not reordered with older loads. 4. Loads may be reordered with older stores to different locations but not with older stores to the same location. 仔细想想,这样的约定正是尽量较少软件可观察的差异体现。作为软件,我们期待写一个变量下一次读出同样的值,所以约定 Store/Load 在同一个内存地址不会有 reorder 。与此同时,写一个变量然后读取另一个变量会有 reorder ,这似乎对软件产生的麻烦就小很多。 最后,为啥非要 reorder ?那当然是硬件那边优化和实现的考虑了,CPU 一般会通过[store buffer]( https://en.wikipedia.org/wiki/Write_buffer)来批量写内存提升效率,不难想象,Store/Load reorder 的存在,不就是顺理成章的事情了嘛。当然,这里对为什么这么约定的解释,更多只是举一个例子的意思,没人真正知道这是不是 Intel 选择上述约定的动机或者唯一动机,重要的只是这个约定是啥样,和我们如何用这个约定解释程序行为。 |
 |
13
dangyuluo OP |
 |
14
nlzy 2022-04-08 23:40:15 +08:00 “这种重排是不可能发生的”,“CPU 某个核心上的指令重排现象”。我认为此处“重排”楼主意指内存乱序。
“多核 CPU 也是可以对指令进行重排的”,“CPU 是可以把指令重排成如下顺序”。我认为此处“重排”楼主意指乱序执行。 仅仅是“重排”这一词的使用就出现了混乱,主楼的其他部分就更不值得细细推敲了。我以为此处的混乱,正是楼主感到迷惑的根源:即使没有乱序执行,store buffer 就足以导致写读乱序。即使指令集架构保证读读连贯,也不能说明微架构没有投机加载。这两个东西就是风马牛不相及。更何况内存顺序是指令集架构定义的,而乱序执行是微架构的具体特性,连抽象层面甚至都不是一个层级。把两个根本不相干的事物混淆在一起,不感到迷惑才奇怪呢!不仅迷惑了自己也迷惑了读者,所以也不怪楼下有老哥留下“一顿胡扯”,“看着头大”的暴躁回复。 一个混乱的问题真的很难去回答,建议楼主可以把自己帖子里的“重排”一词,换成指代更清晰的“编译器重排”、“乱序执行”或“内存乱序”后再重新提问。同时诚挚向楼主安利《 A Primer on Memory Consistency and Cache Coherence, Second Edition 》一书以正视听。 |
|
15
dangyuluo OP @nlzy 。。。之所以不知道用哪个词是因为我没有讲中文的同事,所有人都用 reorder 。不过你有一句话我觉得有道理:
> 即使没有乱序执行,store buffer 就足以导致写读乱序。 我一直将 store buffer 和 invalid queue 当作 MESI 的一部分,可能确实混淆了某个概念,所以还是需要别人指点迷津 |
|
16
dahakawang 2022-04-09 01:54:23 +08:00
看见很多同学推荐了 A Primer on Memory Consistency and Cache Coherence 。这是个很好的教程,但是它可能不能直接用来回答 OP 的问题。因为全文是基于一个假想的 CPU 架构(或者说,至少实现上不见得是和任何一种现实的 CPU 完全一致的),一个例子是随着教程引入了 store buffer 和 invalidate queue 的概念之后,在文中所述的架构中,例子代码需要添加两个 barrier 才能确保正确(section 4.3),然而在 x86 下那两个 barrier 并不是必要的,因特尔关于他们内存模型的白皮书中有过一样的例子。。。
所以除非 OP 真的只是在讨论某一个教程中的架构,如果我们要讨论任何一个真实的架构的话,就回到我之前的观点了,对于 OP 的问题解答,我们很难去诉诸某个架构的某个 specific implementation ( store buffer 也好,invalidate queue 也罢),因为外人很难知道 CPU vendor 具体的实现是啥。唯一公开的只有前文提到的那个约定, 或者叫它某个 CPU 架构的内存一致性模型,OP 的问题可能只能诉诸于具体某个架构实现的某种一致性模型。(当然,模型反过来也某种程度上 imply 了实现) |
|
17
dahakawang 2022-04-09 02:14:59 +08:00
哈哈,睡太晚了发觉居然把文章名字搞混了,我上面是说《 Memory Barriers: a Hardware View for Software Hackers 》另一篇不少人推荐的教程... 但是结论不变 :-)
|
|
18
secondwtq 2022-04-09 02:47:27 +08:00
@dahakawang 楼主问的是“多核 CPU”中 memory ordering 问题的成因,也就是问的就是实现层次的东西。文章并没有特指是哪一个 CPU 。也并没有“假想”“一个”架构,而是在前半部分通过“假想”了“若干”个架构,讲 memory ordering 问题是怎么出现的,后半部分从内存模型的层面(这就不是实现层面了)分析了从 Alpha 到 x86 等若干实际存在的架构,基本套路讲明白了。
要是真就只看一个特定架构的话那倒简单了,直接看 spec 就可以。但是 spec 只是 spec ,不会给你讲什么缓存啊 MESI 啊,根本就没必要关心究竟是怎么执行的,现在重新看一下主题中最后一句话,楼主这个问题的意义在哪里? |
|
19
secondwtq 2022-04-09 03:08:28 +08:00
既然没有办法获知真正的具体实现细节(当然现在有一些开源 CPU 代码可以看),那要想更好的理解 spec (不管是一个特定架构的还是不限于特定架构或平台的,general 的 memory ordering 的 idea )只能建立一个尽可能细致的思维模型来逼近真正的实现,这个模型并不需要与实现相同,它只需要能够自洽地解释“spec 为什么会这么写”的问题就行了。也就是说楼主想要的其实正是 spec 所 “imply” 的那部分。
就特定硬件的实现细节来说,国外也有一些人在做比这个更细节的事,从猜测 die shot ,测量 OoO 结构参数,到研究 microcode 和未公开的接口和优化。甚至还有人翻各种专利加一堆 microbenchmark 凑出来一个 350 页的 M1 分析。猜出来的东西真能和实现对上么?不一定。但是这不重要,有总比没有好。 |
|
20
dangyuluo OP @dahakawang @secondwtq 感谢分析,后来我又从一篇 follow up 文章里找到了相关答案,可能是学艺不精吧,问的问题都难以让人理解。
https://preshing.com/20120710/memory-barriers-are-like-source-control-operations/ |
 |
21
ivechan 2022-04-09 23:55:12 +08:00
@dahakawang 《 A Primer on Memory Consistency and Cache Coherence 》 没有问题吧。
介绍的都是实际中常见的内存模型,比如 X86 ( TSO )。 这个和某个 specific implementation 没有任何关系. 正如 @nlzy 说的一样,内存模型是一个架构的规范,和微架构实现没有关系。 所有 x86 都是 TSO 的,没有什么例外。 |
|
22
ivechan 2022-04-10 00:02:21 +08:00
《 A Primer on Memory Consistency and Cache Coherence 》可以滤清概念
偏实践的话可以看 https://www.kernel.org/doc/Documentation/memory-barriers.txt (怎么用 MB ) |