
这是一个创建于 479 天前的主题,其中的信息可能已经有所发展或是发生改变。
这篇文章将主要描述,如何使用我最近新开发的 WAL ( Write Ahead Log )构建属于你自己的 KV 存储引擎。
什么是 WAL ?
wal ,即 Write Ahead Log ,通常叫做预写日志,在一般的数据库或者存储系统中,是为了预防崩溃恢复而存在的,以传统的 LSM 和 Bitcask 存储引擎为例,数据首先进入存储引擎时,会先写到 WAL 中,然后再更新内存索引,LSM 一般是跳表,而 Bitcask 一般是哈希表,当然你也可以选择其他的内存数据结构。
这样当系统重启时,会通过重放 wal 日志来构建内存数据结构中的内容。
在 Bitcask 存储引擎中,有一个非常特殊的地方在于,预写日志 wal 和实际存储数据的日志文件,其实就是同一个文件,这样便带来一个极大的好处,那就是我们可以直接基于 wal 构建出一个轻量、快速、简单可靠的 KV 存储引擎。
而在 LSM 存储引擎中,会稍微复杂点,因为其后还有 SSTable 这一大块内容,所以本文将会简单起见,只介绍下如何构建 Bitcask 存储,当然如果你在 LSM 中使用了 Wisckey 这样的优化技术后,也可以使用 wal 来存储 kv 分离之后的 Value Log 文件。
WAL 的由来
最开始想开发这个项目,其实主要是想到要重构 rosedb 和 lotusdb ,然后这其中有很多重复的内容,rosedb 的数据文件可以用 wal 来存储,lotusdb 中 Memtable 对应的预写日志,和 Value Log 也可以用 wal 来存储。
因为这几种类型它们的存储格式都是一样的,即日志追加( append only )。所以我将这个公共的部分单独提取出来,形成了一个新的项目。
WAL 的大致结构
然后我们再来看一下 wal 项目的大致结构,一个 wal 实例,其实分为了多个文件,每个文件叫做一个 Segment ,这个 Segment 具体有多大,是可以在启动时配置的,默认是 1GB 。
Segment 文件是分为了多个旧的文件,和一个当前活跃的文件,新写入的数据,会写到活跃的 Segment 文件中。
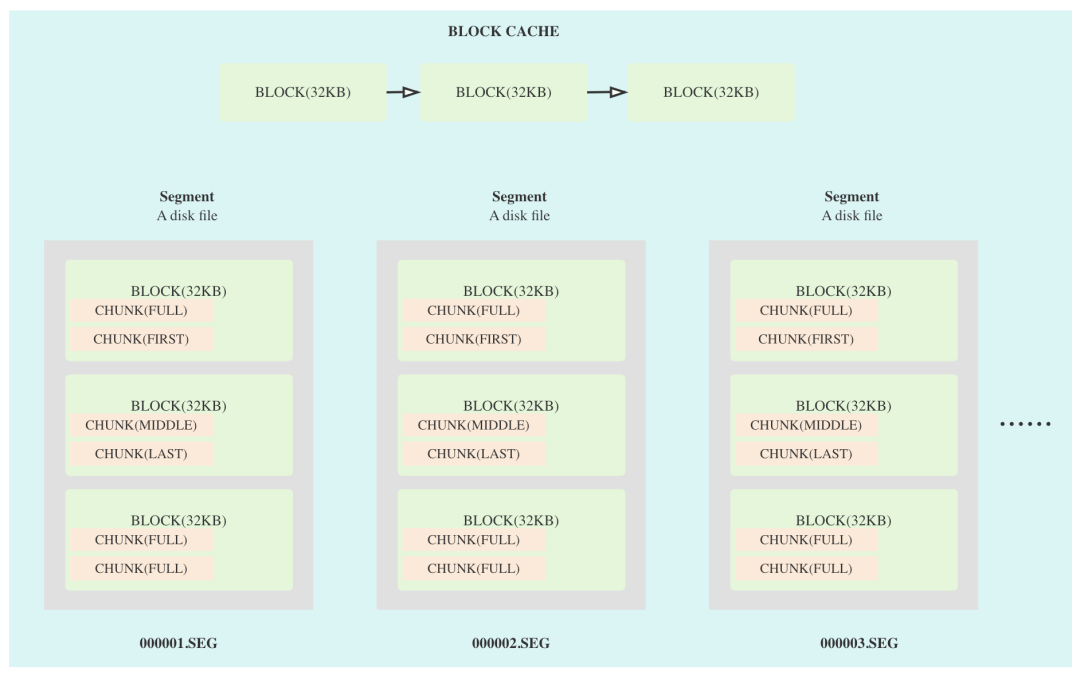 一个 Segment 文件内部,又分为了 n 个等分的 block 块,每一个 block 块的大小是 32 KB 。block 写的是变长的 chunk 数据,一个 chunk 主要是有固定的 7 字节的头部,以及其后的实际的用户存储的数据。每个 chunk 都分为了四种类型,分别是 FULL 、FIRST 、MIDDLE 、LAST ,这主要是借鉴了 Leveldb/RocksDB 中的 wal 的设计。
一个 Segment 文件内部,又分为了 n 个等分的 block 块,每一个 block 块的大小是 32 KB 。block 写的是变长的 chunk 数据,一个 chunk 主要是有固定的 7 字节的头部,以及其后的实际的用户存储的数据。每个 chunk 都分为了四种类型,分别是 FULL 、FIRST 、MIDDLE 、LAST ,这主要是借鉴了 Leveldb/RocksDB 中的 wal 的设计。
数据在写入到 wal 中后,会得到一个 ChunkPosition ,这个 Position 是描述数据在 wal 中的位置信息,你可以直接使用这个位置信息从 wal 中通过 Read 方法读取到写入的数据。
如何基于 wal 构建 KV 存储
从前面的描述中,可以看出,wal 其实就是由多个 Segment 文件组成,支持日志追加写数据,并且可以从中读数 据的一个服务。
这几天集中优化了一下 wal 的读写性能,目前的读写速度很快,并且几乎不怎么占据内存。
有了这个 wal 组件之后,我们再基于此构建一个 Bitcask 存储引擎,将会变得极其的简单。
首先,我们要做的就是选择一个内存数据结构,比如 B-Tree 、跳表、红黑树、哈希表等等都是可以的,只要是能够存储一个 KV 值即可。
用户写入数据,实际就是先写入到 wal 中,写到 wal 之后,你会得到一个位置信息 ChunkPosition ,然后把 Key+ChunkPosition 存储到内存数据结构中即可。
然后是读数据,直接根据 Key 从内存数据结构中获取到对应的 ChunkPosition ,然后根据这个位置从 wal 中读取到实际的 Value 即可。
最后是重启数据库,需要调用 wal 中的 NewReader 方法,这个方法可以遍历 wal 中的所有数据,并返回 Key+ChunkPosition 信息,你只需要把这个数据再次存放到内存数据结构中就可以了。
这几个主要的步骤一完成,一个最基础的 KV 存储引擎就构建起来了,当然你还可以基于此做很多的完善和优化。
好了,这就是基于 wal 这个组件来构建你自己的 KV 存储引擎的大致流程,大家可以自己去尝试动手写一下,对自己的实战能力提升应该还是很大的,觉得项目有帮助的话,欢迎给个 star 支持哦!
 |
1
xycost233 2023-07-31 14:30:36 +08:00
有没有考虑过如果数据量大或者时间线长会导致重启之后的回放过长的问题呢?或者删除 key 之后 WAL 的空间怎么回收,空洞怎么处理呢?
|
 |
2
wkong 2023-07-31 14:42:44 +08:00
|
 |
3
huiwang520 OP @wkong 牛逼,已 star
|
|
4
huiwang520 OP @xycost233 这个一般是存储引擎需要做的事情了,wal 本身一般不会提供这个功能
可以看下 rosedb 的处理逻辑 |
|
5
xycost233 2023-07-31 14:53:17 +08:00
@huiwang520 #4 我的意思是这个项目有没有这方面的考量,是一个 WAL kvdb 的小 demo 么还是有完善的设计,会往大了做
|
|
6
huiwang520 OP @xycost233 这个项目不会有这个考虑,kv 只会用到这个组件,你说的是 kv 层自己需要考虑的事情,可以参考 rosedb
|