
这是一个创建于 572 天前的主题,其中的信息可能已经有所发展或是发生改变。
\x1b 是 linux terminal 和颜色相关的一个前缀
我从 ssh 读出数据做正则匹配 抓到的数据如下:
login: Fri Sep 8 15:48:31 2023 from 127.0.0.1\r\r\n\x1b[?2004h\x1b[1;38m[v12.22.9]\x1b[0m\x1b[1;38mchaleaoch@wsl$:\x1b[
上看是能匹配的. \\x1b\[[0-9;]*[mK]
 但是这个正则放在程序里提示匹配失败.
但是这个正则放在程序里提示匹配失败.
如果改成这样 .*\[[0-9;]*[mK] 提示成功
如果改成这样 (.)\[[0-9;]*[mK] 也提示成功 且(.)对应的字符串是\x1b
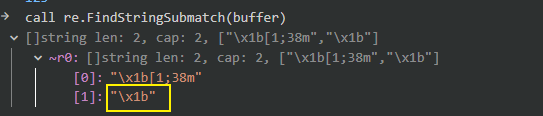
我的问题是如果不用通配符, 我应该如何表达这个转义字符.
第 1 条附言 · 2023-09-08 17:43:58 +08:00
这个解释起来有点麻烦,
感兴趣的热心大佬可以试一下登录自己的 ssh 服务器 用 python 或者 golang
然后将 output 输出看一下 然后抓一下\x1b 或者\033
前提是你的$PS1 是带颜色的.
感兴趣的热心大佬可以试一下登录自己的 ssh 服务器 用 python 或者 golang
然后将 output 输出看一下 然后抓一下\x1b 或者\033
前提是你的$PS1 是带颜色的.
第 2 条附言 · 2023-09-08 19:57:37 +08:00
谢谢大佬们 是我阅读不仔细. 尤其感谢 3 楼 和 9 楼
 |
1
leaflxh 2023-09-08 16:18:08 +08:00
import re
s = "login: Fri Sep 8 15:48:31 2023 from 127.0.0.1\r\r\n\x1b[?2004h\x1b[1;38m[v12.22.9]\x1b[0m\x1b[1;38mchaleaoch@wsl$:\x1b[" r = re.compile(r"\x1b\[[0-9;]*[mK]") #或者 r = re.compile("\\x1b\\[[0-9;]*[mK]") print(r.findall(s)) ['\x1b[1;38m', '\x1b[0m', '\x1b[1;38m'] |
|
2
leaflxh 2023-09-08 16:20:22 +08:00
提版本号
r = re.compile("\\x1b\\[[0-9;]*[mK](.*?)\\x1b\\[[0-9;]*[mK]") >>> print(r.findall(s)) ['[v12.22.9]'] |
 |
3
yuankui 2023-09-08 16:23:33 +08:00 ```
>>> import re >>> >>> # 原始字符串 >>> text = 'This is a string with \x1b some escape sequences \x1b[1;31m embedded.' >>> pattern = re.compile(r'\\x1b') >>> >>> matches = pattern.findall(text) >>> >>> print(matches) [] >>> >>> pattern = re.compile(r'\x1b') >>> matches = pattern.findall(text) >>> print(matches) ['\x1b', '\x1b'] ``` |
 |
4
YGHMXFAL 2023-09-08 16:24:36 +08:00
(\\x1b)\[[[:digit:];]*m
然后\1 就是\x1b 另外"放在程序里提示匹配失败",这个"程序"是啥?它本身会不会还有转义反斜杠的动作?如果是,你需要再多转义一次 regex 表达式-->你的程序-->regex 解析器,你需要保证,经过你的程序(可能存在转义动作)之后,传递给 regex 解析器的依然是你以为得那个表达式,尤其是在交互式 shell 中 |
|
5
yuankui 2023-09-08 16:25:46 +08:00 你应该想法搞清楚 r'\x1b' 和 u'\x1b' 的区别
|
 |
6
chaleaochexist OP |
 |
7
zzl22100048 2023-09-08 18:02:17 +08:00 import re
msg=b"login: Fri Sep 8 15:48:31 2023 from 127.0.0.1\r\r\n\x1b[?2004h\x1b[1;38m[v12.22.9]\x1b[0m\x1b[1;38mchaleaoch@wsl$:\x1b[" print_msg=msg.decode('utf-8') print(print_msg) for item in re.findall(rb'\x1b\[[0-9;]*[mK]', msg): >>print(item.decode('utf-8')+'abc') 没问题啊,终端输出 bytes ,直接用 rb 匹配 |
 |
8
qeqv 2023-09-08 18:02:44 +08:00 最前面的反斜杠去掉
\x1b\[[0-9;]*[mK] |
 |
9
Belmode 2023-09-08 18:04:02 +08:00 编程语言入门问题...
#3 #5 好好看看你就就明白了 |
 |
10
NessajCN 2023-09-08 18:40:48 +08:00 via Android
不同语言对 unicode 字符的正则语法有区别的
|
|
11
qeqv 2023-09-08 18:46:38 +08:00 字符串转义可以处理 \x1b 为对应 ASCII 字符,正则引擎也可以处理,所以不需要管这个字符。
你应该注意的是后面的 \[ ,由于要完整输入 \[ 到正则引擎,所以如果字符串会被转义,那就得 \\[ ,如果不会被转义,就直接 \[ |