
这是一个创建于 549 天前的主题,其中的信息可能已经有所发展或是发生改变。
本文首发公众号:小码 A 梦
一般数据主要存储的形式主要有两种,一种是数组,一种是链表。数组是用来存储固定大小的同类型元素,存储在内存中是一片连续的空间。而链表就不同于数组。链表中的元素不是存储在内存中可以是不连续的空间。

链表主要有两个元素:结点和指针。结点是存储数据,指针是指向下一个结点数据。
链表的有几个特点:
- 不必按顺序存储数据,使用指针关联各个结点的数据。
- 插入数据时间复杂度 O(1)。
- 单链表查询时间复杂度为 O(n)。
JDK 链表源码
JDK 很多地方用到了链表,这里举例两个:HashMap 和 LinkedList 。
HashMap
HashMap 基于数组 + 链表/红黑树的数据结构,其中链表用 Node 表示。主要存储数据和指向下一个结点的指针,源码如下所示。
//HashMap Node 部分源码
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
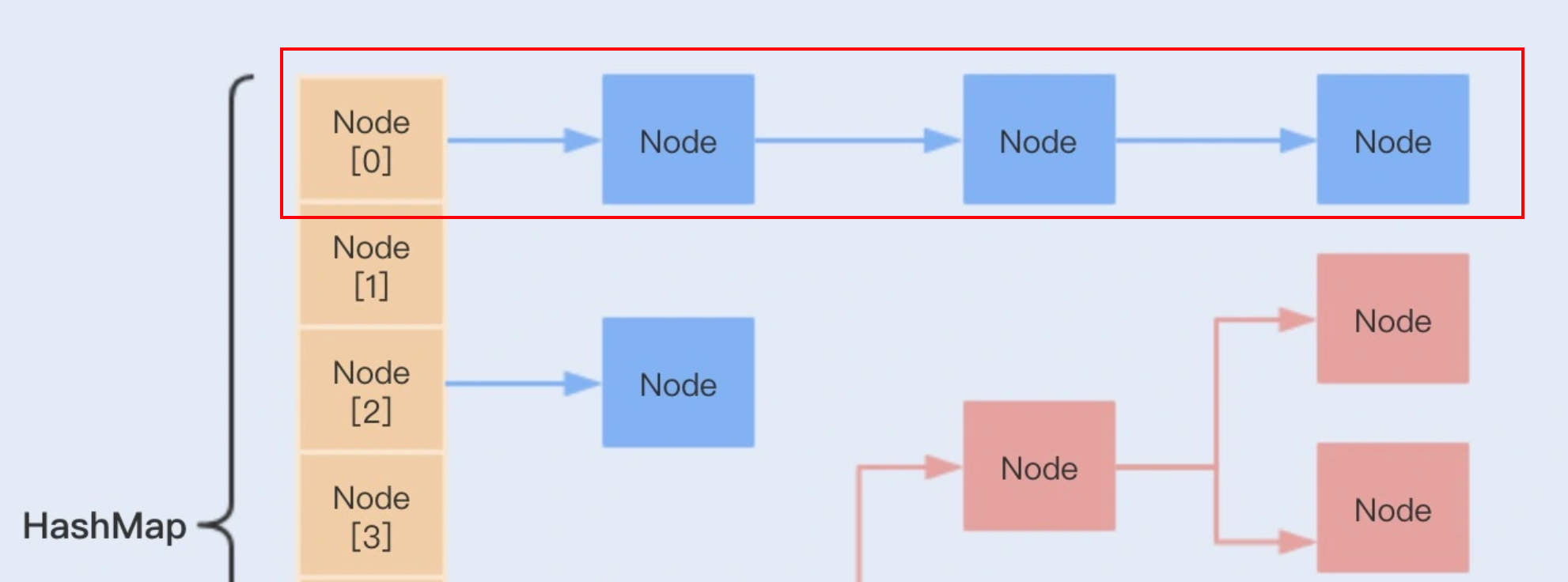
以上蓝色的 Node 结点表示一个链表结点。
LinkedList
LinkedList 本身就是一个双链表,有前置指针和后置指针。
//LinkedList 部分源码
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
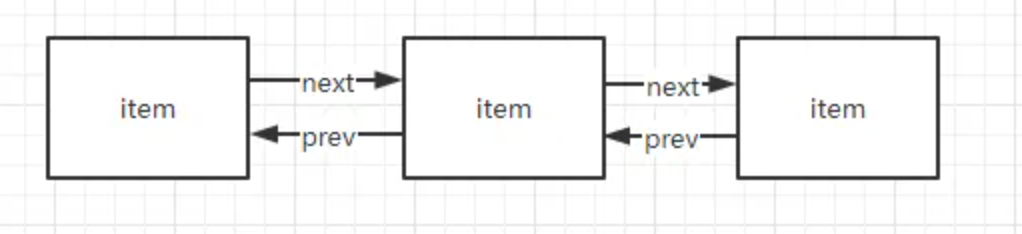
LeetCode 题解
LeetCode 有很多链表的题目,选取了几种比较典型的链表,面试的时候也经常会问到。
206.反转链表(简单)
题目描述

解法
链表结点不变,将指针方向反转。如果只是在一个链表的上操作,每次都需要遍历结点,比较繁琐。所以添加一个空链表 pre 。pre 表示将指针向后,改成向前。比如 1 -> 2 变成 2 -> 1 ,先将 1 放在新的链表上,然后再将 2 放入新的链表,并指向 1 。如下图所示:
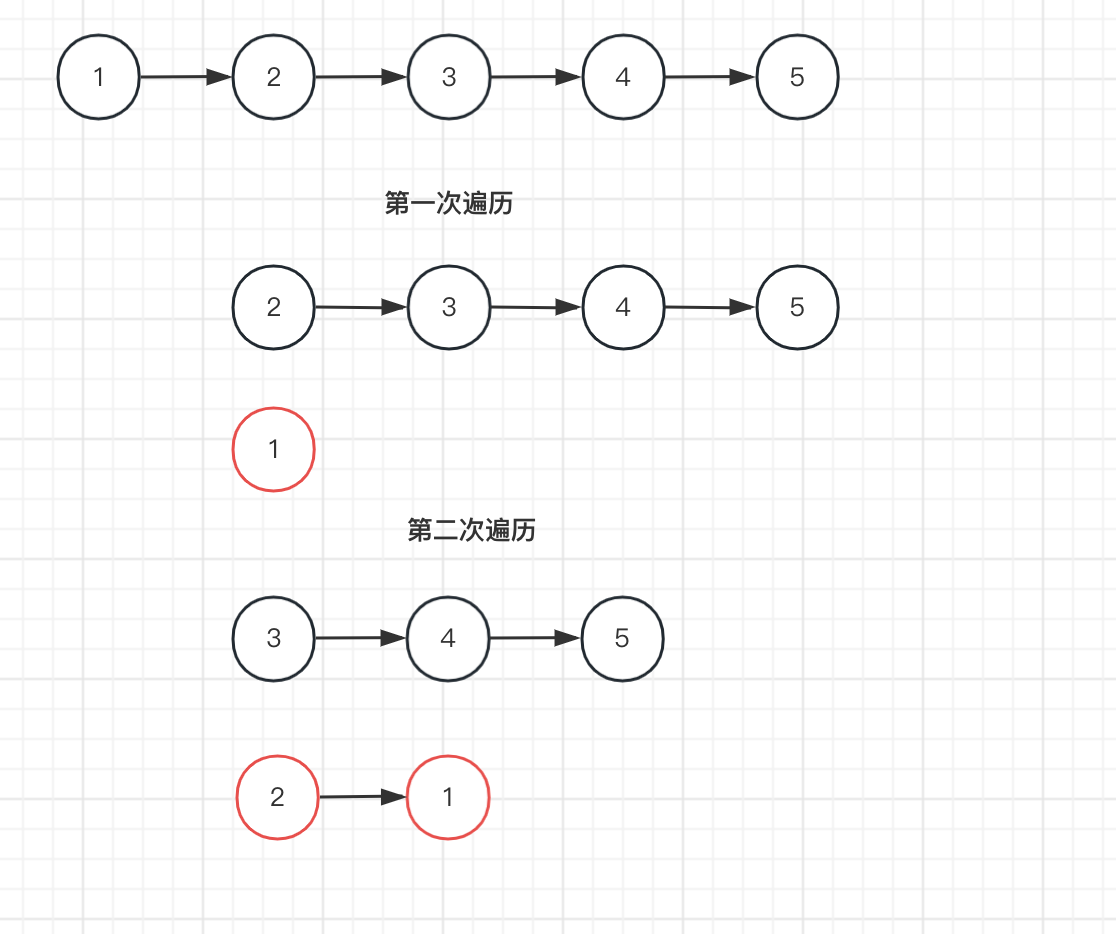
总结一下解决步骤:
- 设置一个空链表 pre
- 遍历链表,每次先将链表的 next ,赋值给一个新的链表。
- 链表的 next 指向 pre 。
- 当前链表赋值给 pre 。
- 继续遍历 next 链表
整理好解题思路后,根据解题写出以下代码:
class Solution {
public ListNode reverseList(ListNode head) {
ListNode cur = head;
ListNode pre = null;
while(cur != null) {
ListNode next = cur.next;
cur.next = pre;
pre = cur;
cur = next;
}
return pre;
}
}
19.删除链表的倒数第 N 个结点(中等)
题目描述

解法
类似链表删除结点,都是修改指针指向的结点,比如删除 4 结点,就需要将 4 节点之前的结点的指针,指向 4 的下一个结点。
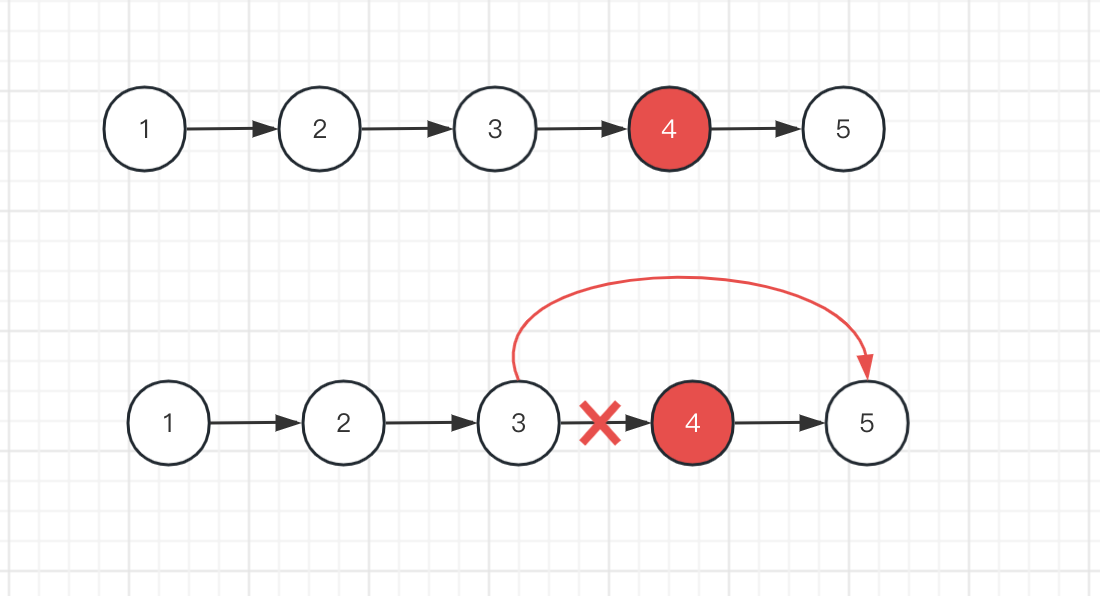
解题的关键点就是找到结点的位置,并修改指针的指向,使用 node.next = node.next.next 即可修改指针的指向。找到结点的位置需要找到链表的长度,然后遍历链表,找到对应结点并修改指针。如果移除的是首结点,就找不到上一个结点,所以需要设置一个伪结点。总结一下解题思路:
- 创建伪结点,next 指向链表。首结点就是一个为伪结点。
- 遍历链表获取链表长度。
- 获取结点位置就是 L-n+1 。
- 遍历链表,找到前一个结点的位置,也就是 L-n 的结点的 next 指向 next.next.返回伪结点的 next 结点。
有了思路,写代码就快了:
class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode cur = head;
int length = 0;
while(cur != null) {
cur = cur.next;
length++;
}
int index = 1;
int sub = length - n + 1;
ListNode dummy = new ListNode(1,head);
cur = dummy;
while(cur != null) {
if(index == sub) {
cur.next = cur.next.next;
break;
}
cur = cur.next;
index++;
}
return dummy.next;
}
}
141.环形链表(简单)
题目描述

解法
环形链表表示链表的某个结点可以通过连续 next 指针再次被遍历到。所以需要做个查重的功能,如果存在重复的结点,就说明链表是一个环形链表。而查重使用 hash 表即可,汇总一下解题思路:
- 遍历结点,将结点添加到 hash 表中。
- 如果在添加数据时发现结点已存在,说明链表是环形链表。
public class Solution {
public boolean hasCycle(ListNode head) {
Set<ListNode> set = new HashSet<>();
while (head != null) {
if (!set.add(head)) {
return true;
}
head = head.next;
}
return false;
}
}
set 的 add 的方法判断是否存在相同的元素,其实是使用 HashMap 的 put 方法,返回之前的数据,如果之前数据不存在就返回 null 。
21.合并两个有序链表(简单)
题目描述

解法
单链表查找结点是需要一个一个往后指针找结点,合并链表的,如果在原来的基础上添加结点就需要不断的遍历结点,合并的链表使用一个新的链表存储。首先找到最小的数据,然后结点存储到新链表,同时断开结点的 next 。如下图所示。
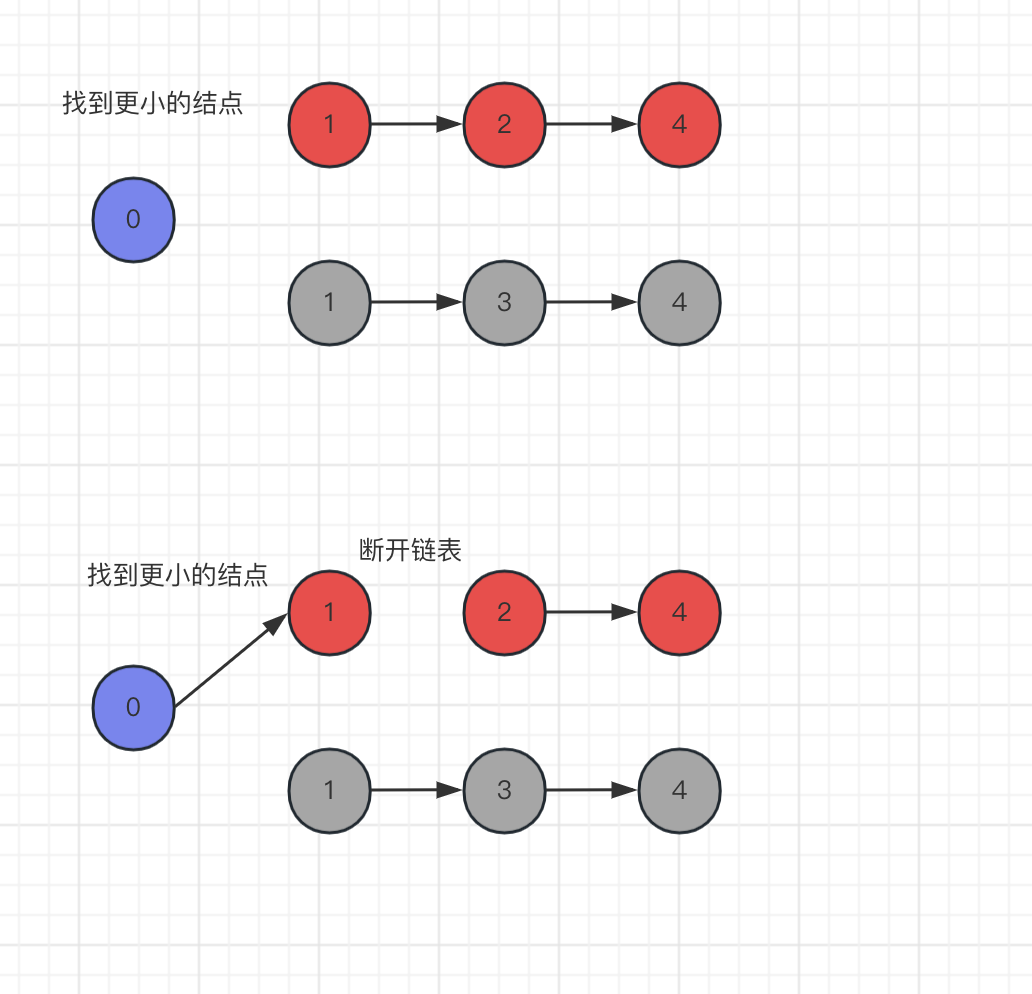
先找到最小的结点,然后新链表(蓝色部分)指向小的结点,然后断开 next 指针。之后的重复类似的步骤。
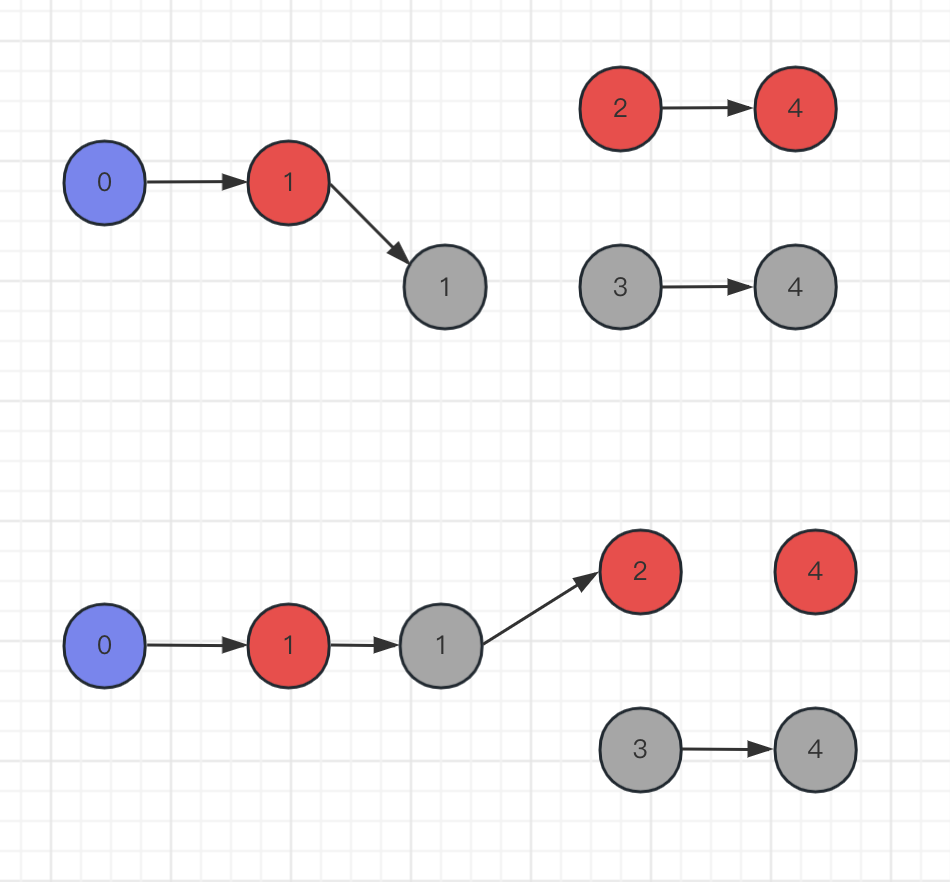
需要考虑到如果某个链表遍历结束了,但是其他链表还有值,就需要遍历非空链表的数据了,最终总结题解的步骤:
- 定义一个新的链表 node ,存储合并的链表。
- 找到最小的结点,新的链表的 next 指向新的结点,并将找到的链表的 next 断开。
- 重复遍历链表,找到最小的节点,直到某个链表为空。
- 一个链表为空,另外不为空,就将链表直接赋值个新链表。
代码如下:
class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
ListNode node = new ListNode(0);
ListNode last = node;
while (l1 != null && l2 != null) {
if (l1.val < l2.val) {
last.next = l1;
l1 = l1.next;
} else {
last.next = l2;
l2 = l2.next;
}
last = last.next;
}
if (l1 != null) {
last.next = l1;
}
if (l2 != null) {
last.next = l2;
}
return node.next;
}
}
总结
链表相对数组来说,在定义的时候不需要确定好内存大小,因为链表的通过指针可以存储非连续空间的数据。链表的查询需要通过指针一个个找到对应的结点,而不能像数组一样通过索引直接找到对应的数据。在 JDK 中也会使用双链表,双链表更占内存,因为多了一个指针,带来的好处是查询数据可以从前往后查,也可以从后往前查,用空间换时间。
主要介绍了几种常见的链表算法:
-
反转链表
- 反转指针方向,结点数据不会改变。 拆分一下数据,1—>2,先将 1 取出来,将 1 作为新链表的头结点,然后再将 2 取出,作为头结点,并指向新的 1 ,此时就完成 2 -> 1 的过程,后续结点以此类推。
-
删除链表的倒数第 N 个结点
- 关键点事要找到要删除的位置,倒数第 N 的节点,也就是链表长度 L-n+1,再修改指针,将自己上一个结点的指针指向自己节点的下一个结点。
-
环形链表
- 环形链表表示存在相同的链表结点,遍历链表,存储在 hash 表,如果存在相同的结点就是环形链表。
-
合并两个有序链表
- 先找到两个链表最小的结点,新的链表指向最小结点,对应的链表去掉指向的结点,以此类推,直到遍历完某个链表。此时如果别的链表不为空,直接指向该链表。
如果感觉不错的话,可以关注一下我的公众号!!

