
Chrome 和 VSCode,每个进程能占用 1T 虚拟内存,有图有真相
richangfan · 2023-07-09 18:38:15 +08:00 · 4052 次点击这是一个创建于 642 天前的主题,其中的信息可能已经有所发展或是发生改变。
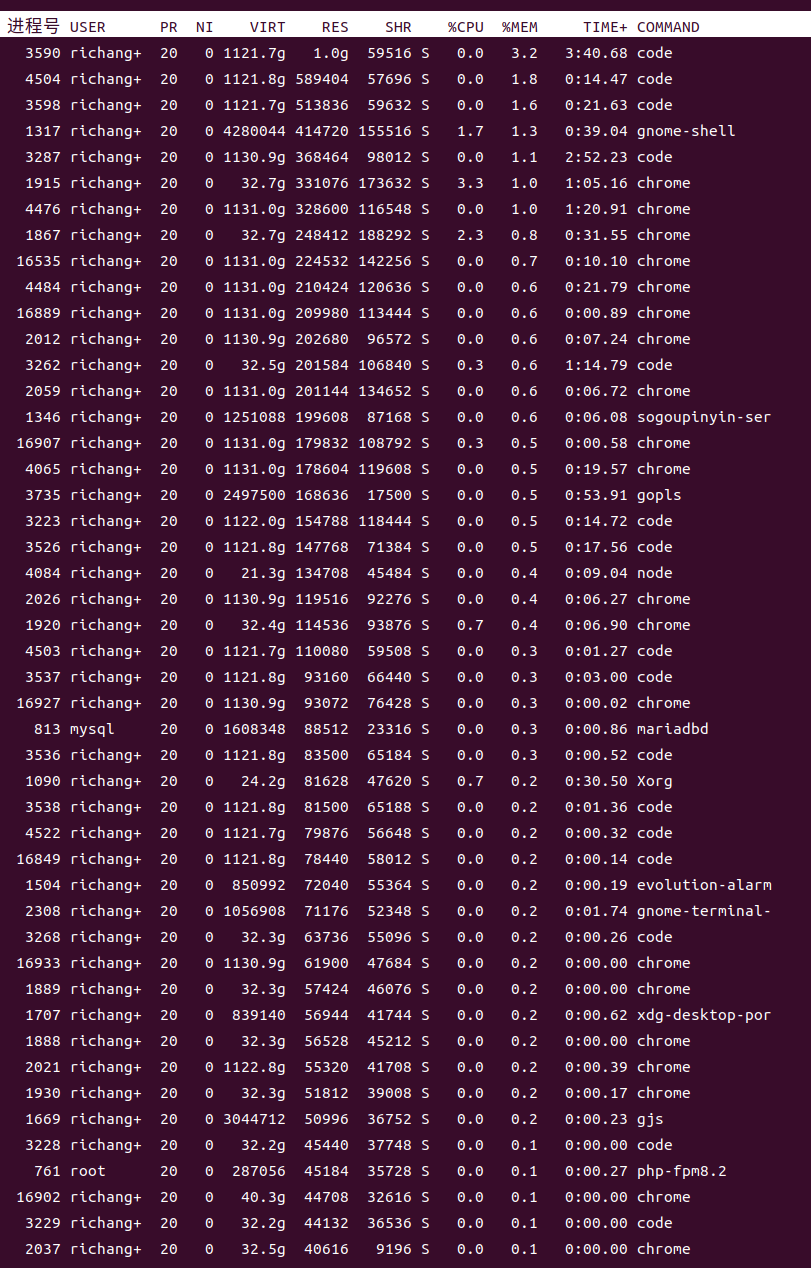
 |
1
codehz 2023-07-09 18:46:05 +08:00
virt 没啥好关注的。。
|
 |
2
wuzhewuyou 2023-07-09 18:47:24 +08:00 via Android
今天下英雄,唯使君与操耳😳
|
 |
3
hsfzxjy 2023-07-09 18:54:18 +08:00 via Android
virt 不能说明什么啊
|
 |
4
infun 2023-07-09 19:04:57 +08:00
virt 只是系统映射给的大小,不代表实际使用的大小
|
 |
5
w568w 2023-07-09 21:58:25 +08:00 via Android
写一行 brk() 把堆顶位置拉满,你的 hello world 也可以占 1TB virt
|
 |
6
systemcall 2023-07-09 23:02:44 +08:00 via Android
virt 这样很正常。我之前用过一个开发板,跑的 64 位系统,一共就几百 MB 内存,还没有 swap 和 zram ,底包自带的一堆东西就几百 G 几百 G 的划 virt ,只能说多亏了是 64 位系统,32 位系统估计早就 oom 了吧
|
 |
7
geekdonie 2023-07-09 23:43:19 +08:00
这就是为啥它叫“虚拟”内存
|
 |
8
yanqiyu 2023-07-09 23:46:59 +08:00 虚拟内存就是纯粹的数字。有些分配器倾向于一启动就 mmap 出来一块超大内存再慢慢分配,所以看起来就是 1T/2T 的 VIRT
但是不真正的读写这些内存,内核是不会真正分配页面的 |
|
10
yanqiyu 2023-07-10 16:22:23 +08:00 via Android
@wxf666 没分配也不会写页表,只是记录下来某段地址成为“可用状态”(代价微乎其微),真正遇到缺页中断才会真正的分配页表
|
 |
11
wxf666 2023-07-10 16:26:44 +08:00
@yanqiyu #10 Emm... 换句话说,申请 1GB 虚拟内存,和 100TB 虚拟内存,操作系统付出的代价,是一样的吗?
|
|
12
yanqiyu 2023-07-10 18:40:10 +08:00
@wxf666 是的,你可以试一下下面的代码,一口气分配 100T ,但是 RES/SHR 依然很小
当然再大就超出了地址空间了 ``` #include <cerrno> #include <iostream> #include <sys/mman.h> int main(int, char **) { constexpr auto size = (size_t)100 << 40; auto address = mmap64(nullptr, size, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS | MAP_NORESERVE, -1, 0); if (address == MAP_FAILED) { std::cerr << "mmap failed \n errno:" << errno << std::endl; return 1; } std::cout << "mmap success, press enter to exit" << std::endl; std::getchar(); munmap(address, size); return 0; } ``` |
|
13
yanqiyu 2023-07-10 18:47:51 +08:00
@wxf666 这也是为什么有的语言的分配器倾向于直接要一个 T 再自己分配,好处就是不用频繁的用 syscall 找 os 要地址,一口气要个大的。
|
 |
14
LiangBryan 2023-07-10 20:35:53 +08:00
没什么好奇怪的,我的电脑也是这样。
|
 |
15
secondwtq 2023-07-27 20:40:34 +08:00 一个典型的例子是 Haskell 的 GHC 编译器,这货(所编译出的程序)在版本 8 之后就是开局分配 1TB 的虚拟内存空间。这是对应的 tracker:gitlab.haskell.org/ghc/ghc/-/issues/9706 #9706: New block-structured heap organization for 64-bit · Issues · Glasgow Haskell Compiler / GHC · GitLab
根据这个 issue 的描述,在之前,GHC 的 allocator 会首先向 OS 申请叫做 megablock 的较大块内存,然后再分成叫做 block 的较小块内存,之后在 block 中处理具体的分配请求。而现在不需要 megablock 这个概念了(或者说只有一个全局的 1TB megablock ),大大简化了实现。 这么做最明显的好处之一是,由于 GHC 使用 tracing GC ,在 GC 时需要检查一个指针是否指向堆中的数据( gitlab.haskell.org/ghc/ghc/-/wikis/commentary/rts/storage/heap-alloced heap alloced · Wiki · Glasgow Haskell Compiler / GHC · GitLab ),因为可能有许多个 megablock ,这个检查在之前是非常麻烦的——他们实现了一套 cache 机制,我觉得很像软件层的 TLB ,先用 tag 去找,找不到再去到表里面搜。而现在只有一个 megablock ,只需要一个全局变量记录它的地址,直接检查是不是在它的 1TB 范围内就可以了(这个应该还可以继续优化,因为理论上你可以向 OS 提出特定的对齐要求,这样直接一个 bitwise-and 搞定)。实现者声称在一些 benchmark 上获得了 8%+ 的提升。注意这个不是靠减少 syscall 得到的。 当然,由于没有了 megablock 的概念,malloc 和 free 的过程也被简化了。 当然,这个 trick 首先需要地址空间足够大,所以只能在 64 位环境下使用。 另外在 Windows 上的实现有些不同,因为 Windows 的 memory overcommitment 似乎和 Linux 上不太一样。 之所以要提 Windows 不只是因为原 issue 上重点关照了这方面,还是因为之前我关注到网络上的一些言论,说最好不要彻底关闭 Windows 的 pagefile ,会导致很多软件出问题,甚至包括 MSFT 官方的一些软件。我一直都很好奇,按理说有没有 pagefile/swap 并不是软件应该关心的问题,如果我 8GB DRAM+8GB pagefile 能正常工作,16GB DRAM 不带 pagefile 不应该更差。看到这个问题就觉得可能跟这个有关系。我的推测是 Windows 下的很多程序可能比较喜欢以当前系统的 DRAM 大小为系数来预分配内存,这样所有程序想要分配的内存总大小很容易超过 DRAM 大小,就必须要 pagefile 来兜个底。但是网上的建议是你哪怕开几 MB 的 pagefile 创建一下全国文明系统都不要彻底关掉,如果真的只有几 MB 的话就没啥作用了。不过 Windows 默认的 pagefile 设置是“系统自动管理”,不够的时候会自动扩容(虽然最多只能 3x DRAM 大小),并且 NTFS 还支持 Sparse file 。另一个因素是现在 Windows 主流软件几乎全员或多或少都要 GPU 加速,而 DRAM 和 VRAM 之间的数据传输也需要 memory map 。还有一个则是根据官方文档,Windows 的 CreateFileMappingW(INVALID_HANDLE_VALUE, ... (类似 MAP_ANON )是"backed by the system paging file",而在 Linux/BSD 上直接出来就是 anonymous page ,但是 Raymond Chen 澄清过( bytepointer.com/resources/old_new_thing/20130301_058_the_source_of_much_confusion_backed_by_the_system_paging_file.htm The source of much confusion: "backed by the system paging file" )这个有很多误会,"backed"是指"page out 的时候会扔到 pagefile 去",这样得到的内存空间其实和 HeapAllocate/VirtualAlloc() 是一样的,也就是说基本是一句废话。目前我没有时间或者没有方法来验证这些猜测,所以这个问题到现在还没搞明白,不知道 V 友有没有清楚具体原因的。 Windows 下还有更加生草的问题——和楼上所关心的“操作系统付出的代价”密切相关。由于 GHC 采用了这种新的内存管理模式,在老版 WSL 上会莫名奇妙地慢到不可用:github.com/microsoft/WSL/issues/1671 `stack ghc` painfully slow · Issue #1671 · microsoft/WSL · GitHub 这个问题后来貌似被修复了,不过可见虚拟内存大小并非在所有情况下都无所谓。上面有人说开发板也可以跑,前提也是开发板的软件是比较成熟的。 此外 Google 的 Go 实现在某些版本似乎也有类似的机制。至于 Chrome 这个事情,https://unix.stackexchange.com/a/741548 Why Google Chrome is reserving Terabytes scale virtual memory? 这个回答指出这和 V8 引擎在近年实现的一个新的安全功能有关。V8 中的一些 bug 可能允许攻击者利用 V8 内部代码实现内存读写,因此这个新的机制会预先分配 1TB 的虚拟地址空间,并将 JS 程序的数据全都分配在这里面,地址则使用 40-bit 数存储。这样就把类似攻击的影响面限制在了这 1TB 范围之内。 最后必须批评类似话题常见的一种风气——对你没有影响就不用管,这属于问了 Y ,然后回答者自作主张去回答 X 。典型是这个帖子:reddit.com/r/linuxquestions/comments/w4im5m/chrome_using_11_terabytes_of_virtual_memory 这里很明显这个 sub 的平均技术水平一般——不清楚虚拟地址空间概念的比比皆是,不过鉴于本身就是 /r/linuxquestions 倒也没啥奇怪的。但是就算虚拟地址空间占用对用户没有什么意义,为什么别的进程都很正常,就你 Chrome 搞特殊呢?这本身就是个很有趣的问题。 |